Syncnet
Note
论文要点解读
网络输入
论文原图:
音频特征
论文每个数据对长度为0.2s,其中音频使用16k采样率的wav,使用13个mel frequency的MFCC特征,时间采样率为100Hz,所以0.2s对应20个时间步的数据(最后形状为13x20)。
视频特征
图像数据为连续的5帧(25FPS)口型区域灰度图像,尺寸为120x120x5。
网络结构
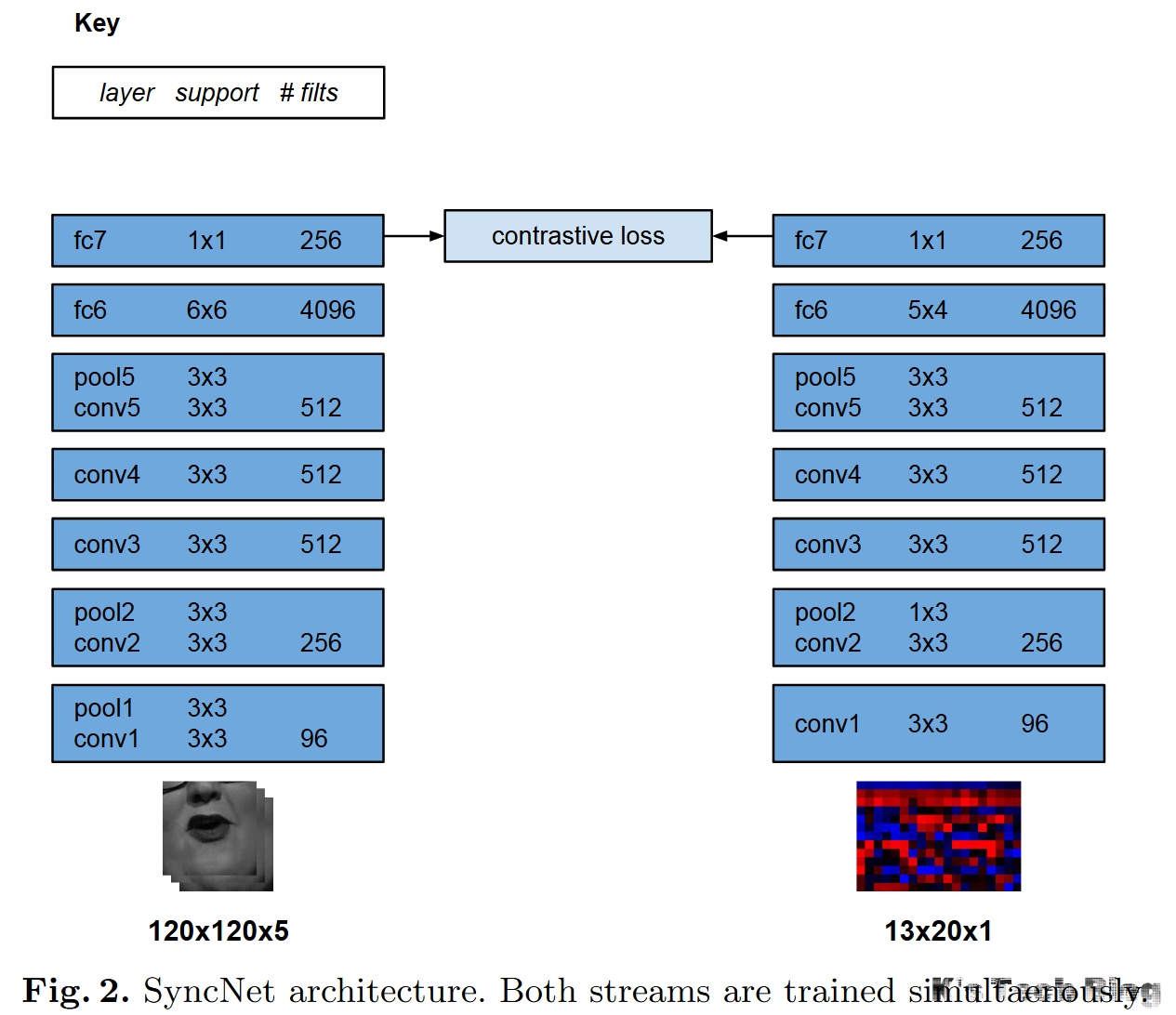
1. 整体逻辑:双塔结构 (Siamese-style Architecture)
这就好比两个不同语言的翻译官:
- 左边的翻译官(视觉流):看嘴型,把嘴部动作翻译成一个“特征码”。
- 右边的翻译官(听觉流):听声音,把语音片段翻译成一个“特征码”。
- 中间的裁判(Contrastive Loss):对比这两个特征码。如果它们原本是来自同一个时刻(同步),特征码应该很像;如果不同步,特征码应该差别很大。
2. 左侧:视觉流 (Visual Stream)
这一侧负责提取嘴部运动特征。
- 输入 (Input):
120x120x5:表示输入的是5帧连续的灰度图像(嘴部特写),每张图大小是120x120。- 为什么要5帧?为了捕捉嘴唇运动的时间动态(不仅仅是张嘴闭嘴的静态图,而是运动过程)。
- 网络层 (Layers):
- 这里使用的是类似 VGG-M 的卷积神经网络结构。
- conv1 - conv5: 不断地进行卷积(提取特征)和池化(Pool,缩小尺寸)。
- fc6 (6x6, 4096): 这里是一个全连接层(实际上是用卷积实现的)。之所以卷积核是
6x6,是因为经过前面5层的池化后,原本120x120的图像刚好被压缩成了6x6大小。这一步将空间特征压缩成了一维的4096尺寸的向量。 - fc7 (1x1, 256): 再次压缩,最终输出一个 256 的向量。这就是“嘴型特征”。
3. 右侧:听觉流 (Audio Stream)
这一侧负责提取语音特征。
- 输入 (Input):
13x20x1:这不是普通图片,而是 MFCC(梅尔频率倒谱系数) 图谱。- 它代表了对应那5帧视频时长的音频片段(大约0.2秒)。
- 13 代表频带(频率维度),20 代表时间步(时间维度)。
- 网络层 (Layers):
- 这也是一个卷积网络,但针对音频图谱的形状做了调整。
- 注意 pool2 (1x3):这里的池化是非对称的。它主要在时间维度上压缩,而保留频率维度的信息,这更符合语音处理的特性。
- fc6 (5x4, 4096): 同样的道理,经过层层压缩,音频图谱变成了
5x4大小。用一个5x4的卷积核处理之后,变成了4096尺寸的向量。 - fc7 (1x1, 256): 最终输出一个 256 的向量。这就是“语音特征”。
监督方式
本文使用了对比损失函数 (Contrastive Loss) 来训练网络,使得同步的音视频片段特征距离尽可能小,而不同步的特征距离尽可能大。
$$\begin{aligned} E=\frac{1}{2N}\sum\limits_{n=1}^{N}(y_{n})d_{n}^{2} + (1-y_{n})\text{max}(margin-d_{n},0)^{2} \end{aligned}$$- $y_n$: 标签。$y_n=1$ 表示音视频同步(正样本),$y_n=0$ 表示不同步(负样本)。
- $d_n$: 欧氏距离 $||v_n - a_n||_2$,即视觉特征和听觉特征之间的距离。
- Margin: 设定的阈值。对于负样本,我们希望它们的距离至少大于这个 margin。
- 训练策略: 正样本来自原始视频,负样本通过在时间上随机偏移音频来构造。
置信度计算 (Confidence Calculation)
在推理阶段(测试或实际使用时),我们不仅仅判断是否同步,还需要计算一个“置信度”分数,用于衡量同步的质量或检测当前视频是否真的是说话人(Active Speaker Detection)。
计算距离序列: 给定一段视频和对应的音频,提取各自的特征。保持视频特征不动,将音频特征在时间轴上进行滑动(例如 $\pm 1$ 秒范围)。在每个时间偏移量(Offset)上,计算音视频特征的平均欧氏距离。
距离曲线: 这样就得到了一个关于时间偏移量的距离曲线。
- 如果音视频同步良好,在 Offset=0(或实际同步点)处,距离应该最小 ($d_{min}$)。
- 在其他错误的偏移位置,距离应该较大且杂乱无章。
置信度定义: SyncNet 定义置信度(Confidence)为最小距离与平均距离(或中位数距离)的差值(通常实现中使用中位数):
$$ \text{Confidence} = d_{median} - d_{min} $$- $d_{min}$: 搜索窗口内的最小距离。
- $d_{median}$: 搜索窗口内所有距离的中位数。
解读: 这个差值越大,说明在某个特定时间点(同步点)的特征匹配程度显著优于平均水平(背景噪声),因此置信度越高。即距离曲线的“峰值”(虽然是距离谷底)越尖锐。