经验总结
问题
生成和判别失衡诊断
在 GAN(尤其是 Image-to-Image / Talking Head)任务中,训练的核心不在于让 Loss 降到最低,而在于维持 生成器 (G) 与 判别器 (D) 之间的动态博弈平衡。
实践案例参考
一个Gan训练任务,数据量比较大,分布比较广,实际训练过程中发现,在达到一定迭代次数之后,生成器网络才开始输出正常的图像,并且因为开启了ttur,导致判别器过早收敛,Gan loss失效。
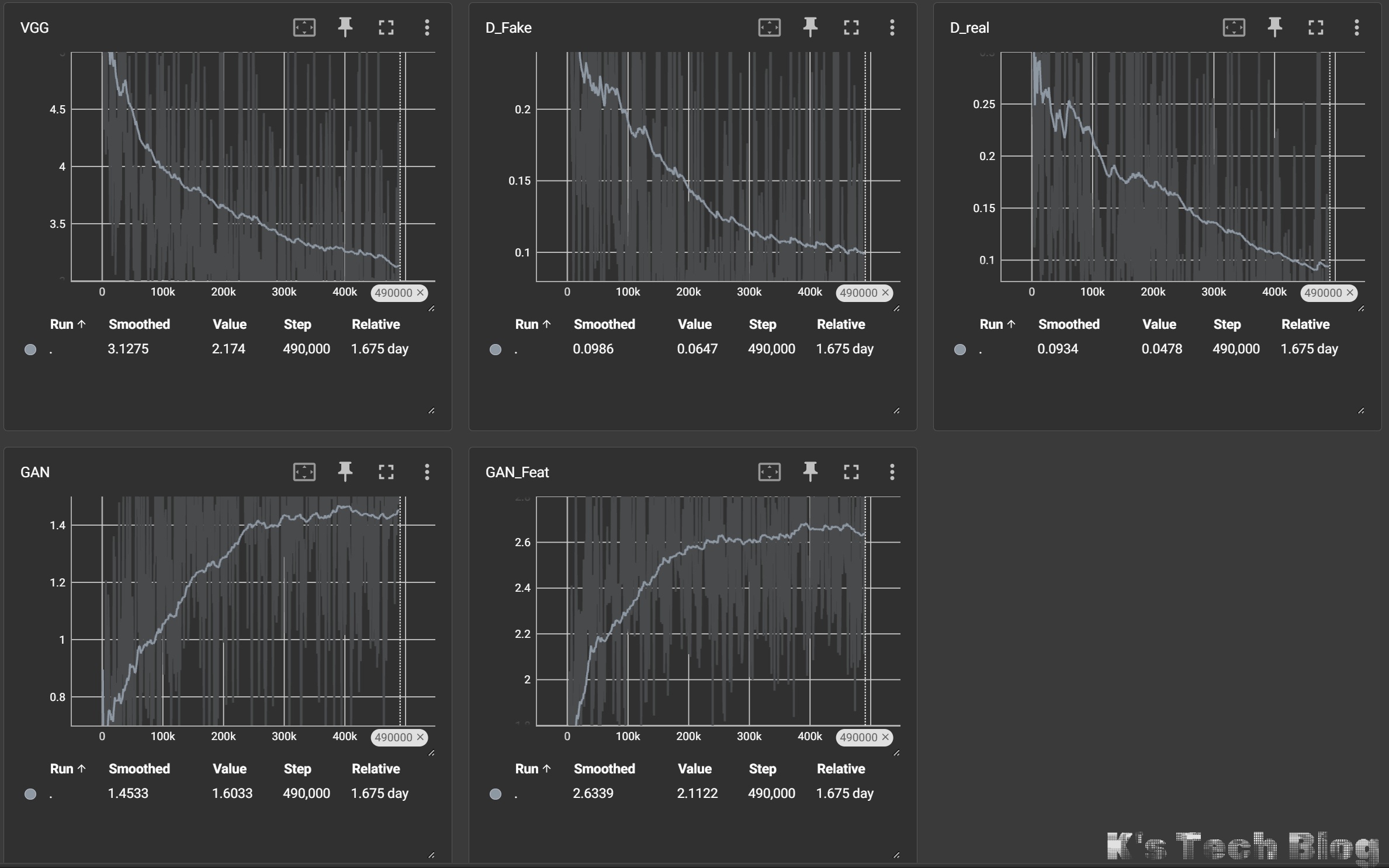
1. 核心 Loss 指标的物理含义
| 指标 | 定义 | 理想状态 | 异常信号 |
|---|---|---|---|
| D_Real | D 对真图的识别能力 | 稳定在 0.1~0.4 之间震荡 | 趋近于 0(D 太强,不放过任何真图) |
| D_Fake | D 对假图的识别能力 | 稳定在 0.1~0.4 之间震荡 | 趋近于 0(D 太强,瞬间识破假图) |
| GAN (G) | G 欺骗 D 的能力 | 与 D 相互拉锯,不持续飙升 | 持续上升(G 彻底失去反抗能力) |
| GAN_Feat | 真假图在 D 特征空间的距离 | 缓慢下降或平稳 | 持续上升(D 把真假特征分得太开) |
| VGG/L1 | 像素/感知层面的重建精度 | 持续下降并收敛 | 不降反升(模型完全崩溃/飞了) |
2. 典型异常诊断:判别器“超神” (Discriminator Overpowering)
现象描述:D_Real 和 D_Fake 极速降至 0,同时 GAN Loss 和 GAN_Feat 持续飙升。
后果:判别器变成了“只会说不的暴君”。由于 D 过于完美,它提供给 G 的梯度变得极其单一且粗暴。G 无法从 D 那里获得“如何变真”的细节指导,只能依赖 VGG/L1 维持基本结构,导致图像缺乏逼真纹理(高频细节丢失)。
3. 大规模数据集(如 20w+)下的训练策略
A. 实施“热身”阶段 (Warm-up Phase)
对于复杂任务,不要从第一步就开始对抗训练。
- 做法:前 0.5~1 个 Epoch(或前几万步)仅开启
VGG、L1等重建损失。 - 目的:让 G 先学会“画出像人的轮廓”,建立正确的空间结构。等 G 的输出达到一定水平后,再开启 GAN 损失进行细节打磨。
B. 灵活调整 TTUR(双时间尺度更新法则)
- 理论:通常设置 $lr_D > lr_G$(如 D:4e-4, G:1e-4),确保 D 跑得快以提供有效指导。
- 现实:如果 D 的架构太强或数据集很大,4 倍的 $lr$ 会瞬间压死 G。
- 修正建议:当观察到 D 过强时,应调低 D 的学习率(降至与 G 持平甚至更低,如 D:1e-4, G:2e-4),强制 D 变“笨”一点,给 G 留出进步空间。
C. 增加判别器的“阻力”
如果 D 依然太强,可以使用以下手段干扰 D:
- 标签平滑 (Label Smoothing):将真图的目标值从
1.0降为0.9。 - 降低更新频率:每更新 2 次 G,才更新 1 次 D。
4. 训练成功的标志
- 客观 Loss (VGG/Dice/L1) 平稳下降:确保模型在做“正确的事”,没有产生乱码。
- 对抗 Loss (GAN/D_Loss) 剧烈震荡:GAN 训练不需要平滑的下降曲线,来回跳动且不往一边倒的曲线代表博弈正在激烈进行。
- 视觉效果:结构先对齐(Warm-up 功劳),纹理后丰富(GAN 的功劳)。
5. 个人感悟(避坑指南)
“GAN 的训练不是为了消灭对手(D 降到 0),而是为了在对抗中共同进步。如果你的警察(D)太厉害了,小偷(G)就只能改行或者摆烂,最后你永远得不到一个高水平的造假大师(高质量生成器)。”