激活函数
Tanh
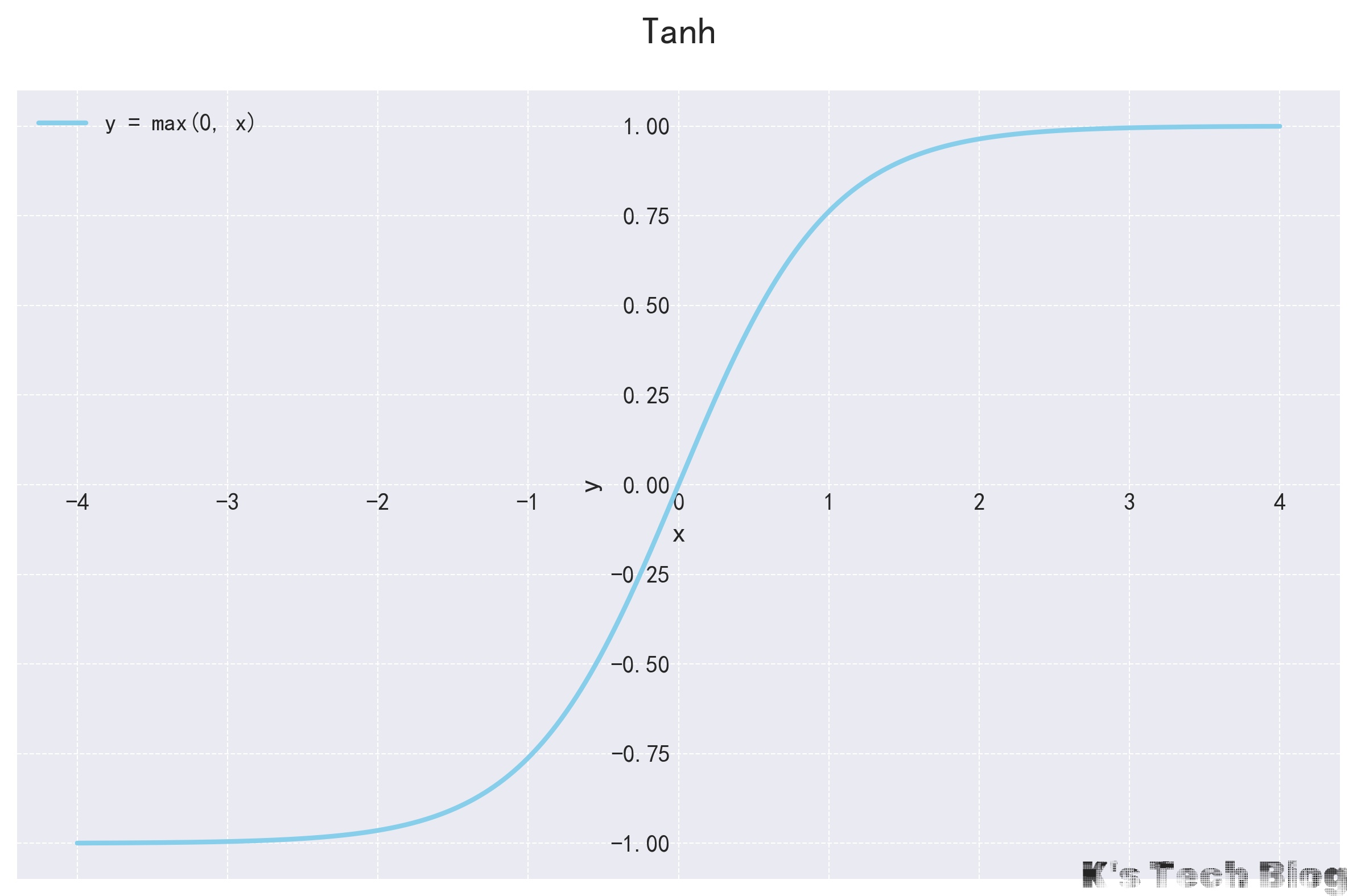
- Tanh(Tangent hyperbolic):双曲正切函数 $$ Tanh(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} $$
Sigmoid
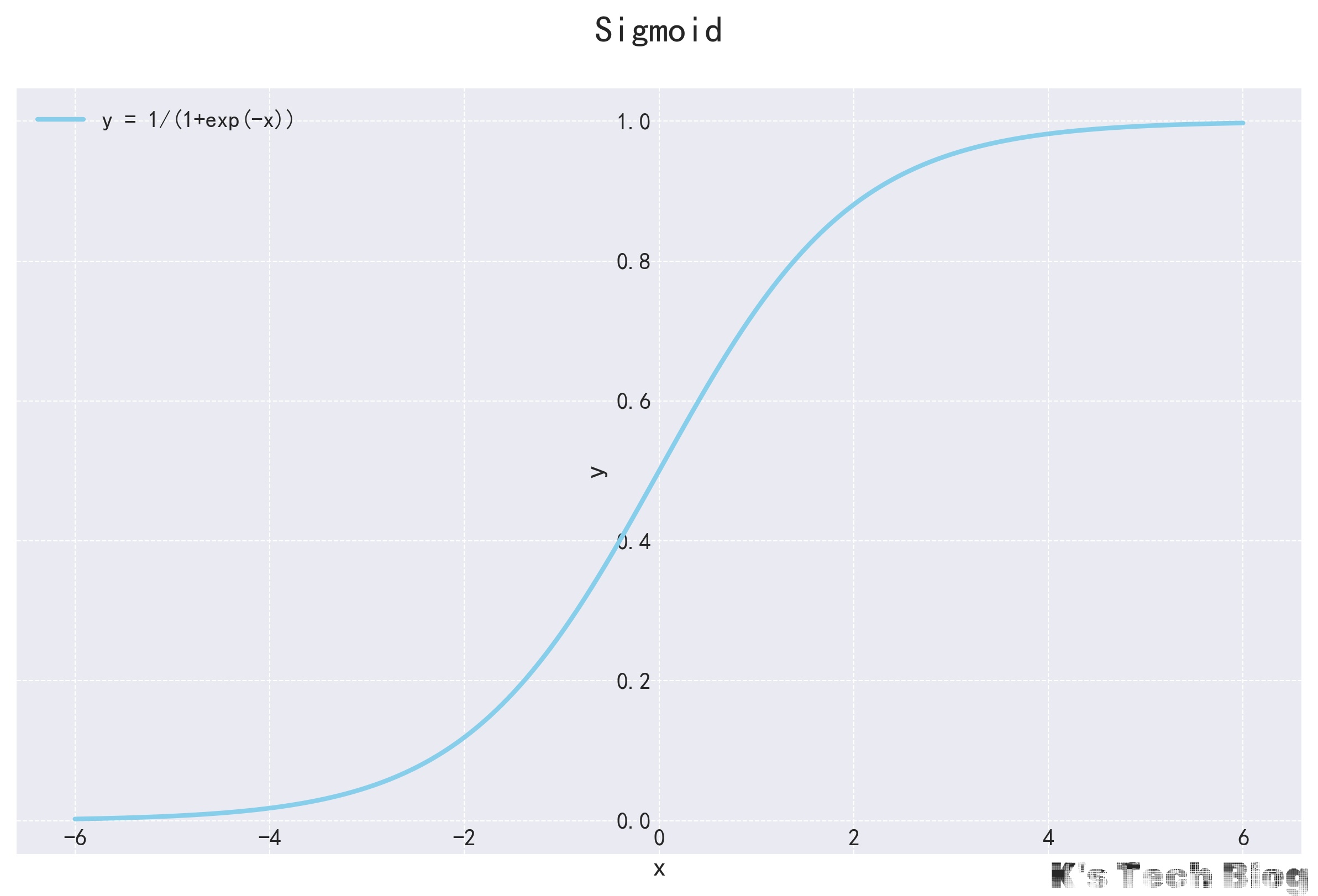
Sigmoid函数,也称为Logistic函数,是一个非常经典的“S”型函数。他的主要作用是将任何实数输入映射到(0, 1)这个开区间内。
- 主要作用:二元分类输出层;早期的神经网络隐藏层。
- 缺点:
- 计算成本高。
- 输出非零中心。
- 梯度消失:$x$极大和极小的时候,梯度接近于0;且每层梯度小的情况下,梯度反向传播越乘越小,最后接近于0(梯度小时),导致优化困难,后面被ReLU系列激活函数替代。
LeakyReLU
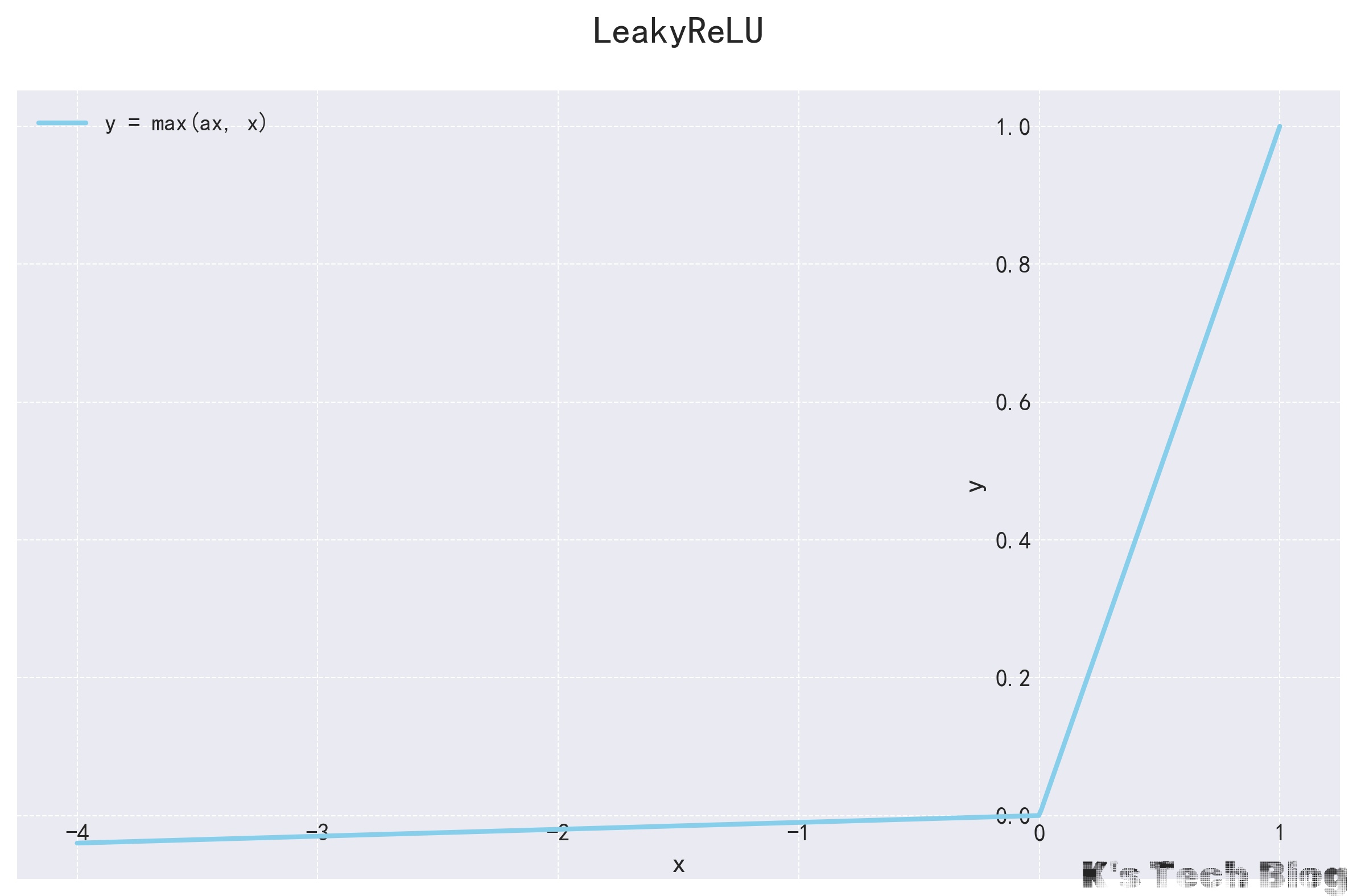
LeakyRelu,全称为“带泄露的修正线性单元”,是经典激活函数ReLU(Rectified Linear Unit)的一个改进版本。- 核心思想是:输入值为负的时候,不再像ReLU那样直接输出0,而是输出一个非常小的、非零的、固定的整数。
- $a$被成为“泄露系数”,通常取值为
0.01,也可以根据需求设置为其他值。
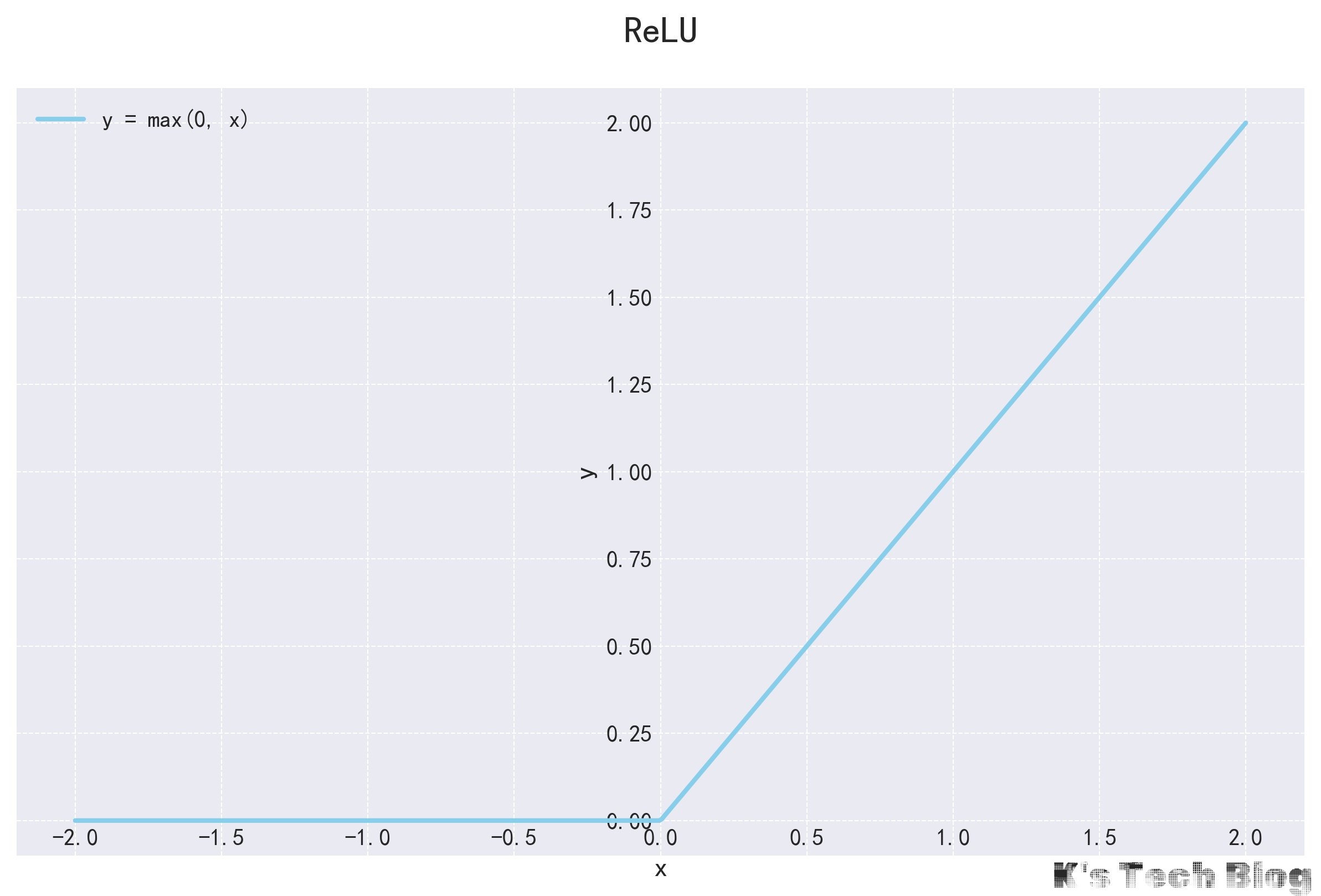
ReLU
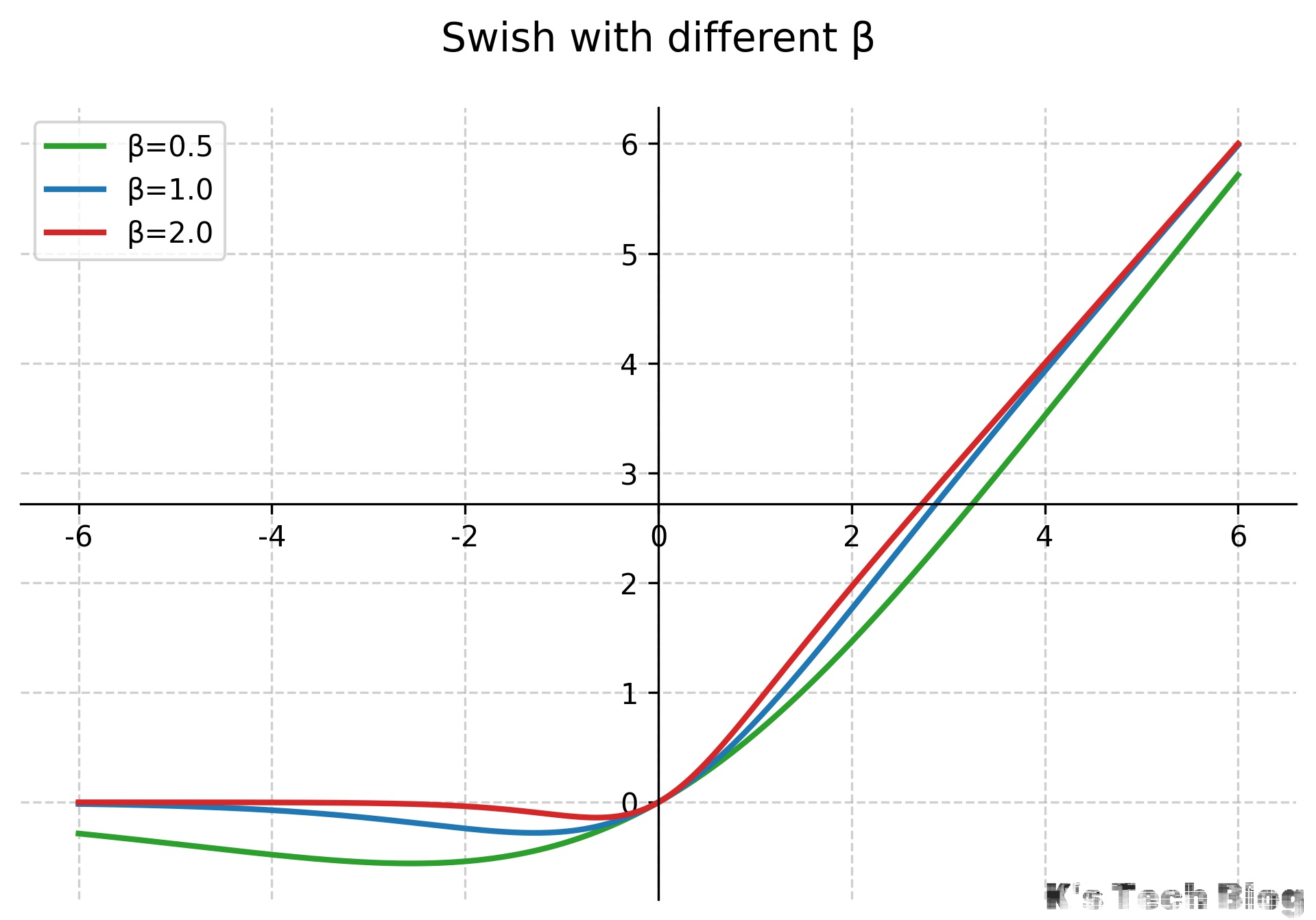
Swish & SiLU
Swish函数由Google Brain团队提出,是一种自门控(Self-Gated)激活函数。
其中$\sigma$是Sigmoid函数,$\beta$是一个可学习参数或常数。
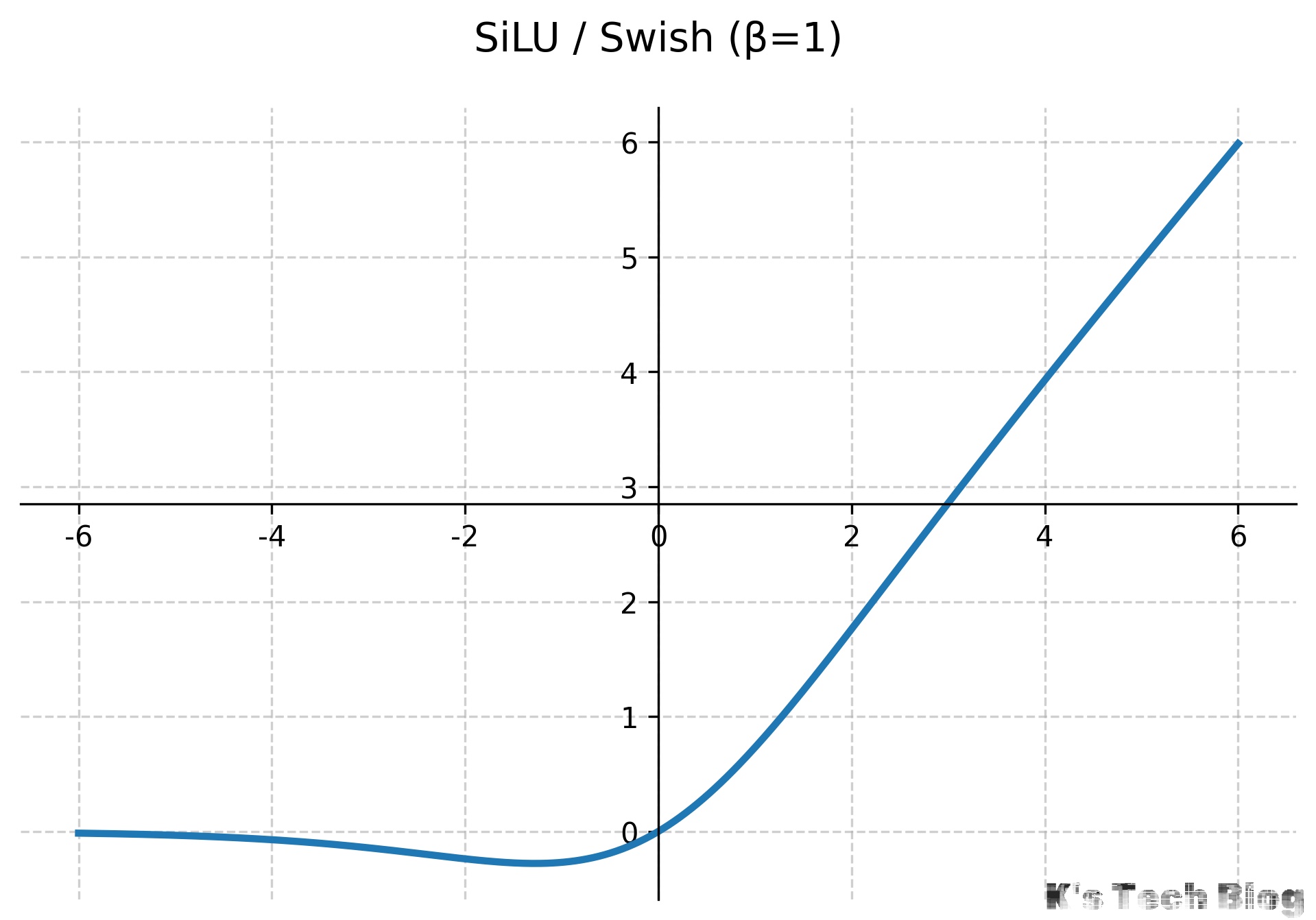
当$\beta = 1$时,Swish函数变为SiLU (Sigmoid Linear Unit):
$$ SiLU(x) = x \cdot \sigma(x) = \frac{x}{1 + e^{-x}} $$- 特点:
- 平滑且非单调:与ReLU不同,Swish在负值区域并在接近0时有非单调性,这有助于梯度的流动。
- 无上界,有下界:类似于ReLU,避免了梯度饱和,同时对负值有正则化效果。
- 在深层模型中通常优于ReLU。
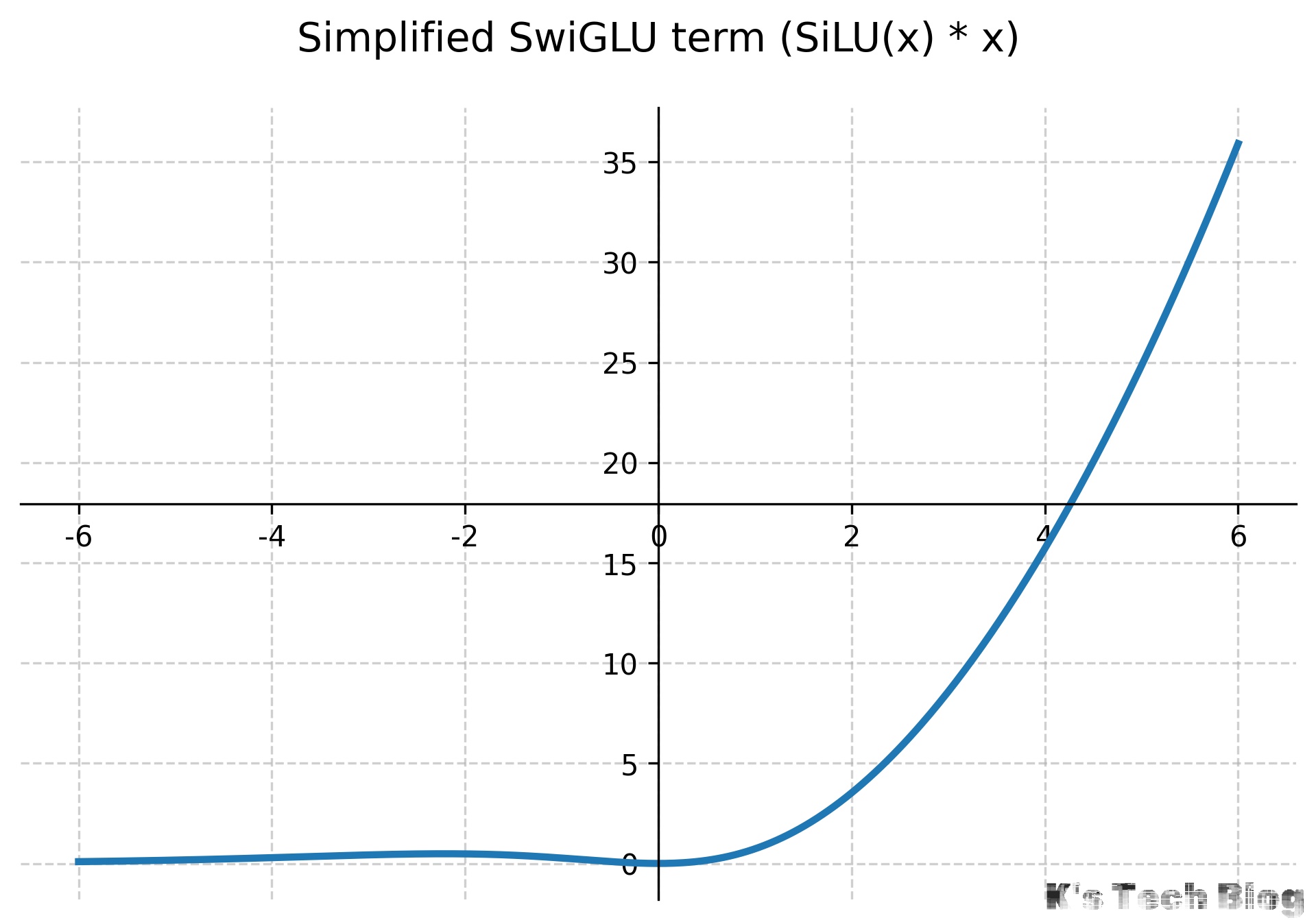
SwiGLU
SwiGLU (Swish-Gated Linear Unit) 是在论文《GLU Variants Improve Transformer》中被提出并在大模型(如LLaMA, PaLM)中广泛使用的激活结构。它是GLU(Gated Linear Unit)的一种变体。
GLU定义为:
$$ GLU(x, W, V, b, c) = \sigma(xW + b) \otimes (xV + c) $$SwiGLU则是将Sigmoid激活函数替换为Swish(通常是$\beta=1$的SiLU),并通常省略Bias:
$$ SwiGLU(x, W, V) = Swish_{\beta}(xW) \otimes (xV) $$在Transformer的FFN层中应用SwiGLU通常如下(输入$x$):
$$ FFN_{SwiGLU}(x) = (SiLU(xW_1) \otimes xW_2)W_3 $$其中$W_1, W_2$将输入映射到隐藏层维度,$W_3$映射回原来的维度。
- 优势:相比标准的ReLU或GELU前馈网络,SwiGLU通常能带来更好的性能和收敛速度。