现有模型信息记录
底模SD1.4
BK-SDM
https://github.com/Nota-NetsPresso/BK-SDM 数据来源:BK-SDM ModelCard
训练信息
训练集:BK-SDM数据
- Training Data
- BK-SDM: 212,776 image-text pairs (i.e., 0.22M pairs) from LAION-Aesthetics V2 6.5+.
- BK-SDM-2M: 2,256,472 image-text pairs (i.e., 2.3M pairs) from LAION-Aesthetics V2 6.25+.
- Hardware: A single NVIDIA A100 80GB GPU
- Gradient Accumulations: 4
- Batch: 256 (=4×64)
- Optimizer: AdamW
- Learning Rate: a constant learning rate of 5e-5 for 50K-iteration pretraining
测试信息
从数据来源拷贝整理 测试集:MS COCO 30k,可以通过BK-SDM的脚本下载或者见文件链接
The following table shows the results on 30K samples from the MS-COCO validation split. After generating 512×512 images with the PNDM scheduler and 25 denoising steps, we downsampled them to 256×256 for evaluating generation scores.
Zero-shot MS-COCO 256×256 30K
- Our models were drawn at the 50K-th training iteration.
| Model | FID↓ | IS↑ | CLIP Score↑ (ViT-g/14) | # Params, U-Net | # Params, Whole SDM |
|---|---|---|---|---|---|
| Stable Diffusion v1.4 | 13.05 | 36.76 | 0.2958 | 0.86B | 1.04B |
| BK-SDM-Base (Ours) | 15.76 | 33.79 | 0.2878 | 0.58B | 0.76B |
| BK-SDM-Base-2M (Ours) | 14.81 | 34.17 | 0.2883 | 0.58B | 0.76B |
| BK-SDM-Small (Ours) | 16.98 | 31.68 | 0.2677 | 0.49B | 0.66B |
| BK-SDM-Small-2M (Ours) | 17.05 | 33.10 | 0.2734 | 0.49B | 0.66B |
| BK-SDM-Tiny (Ours) | 17.12 | 30.09 | 0.2653 | 0.33B | 0.50B |
| BK-SDM-Tiny-2M (Ours) | 17.53 | 31.32 | 0.2690 | 0.33B | 0.50B |
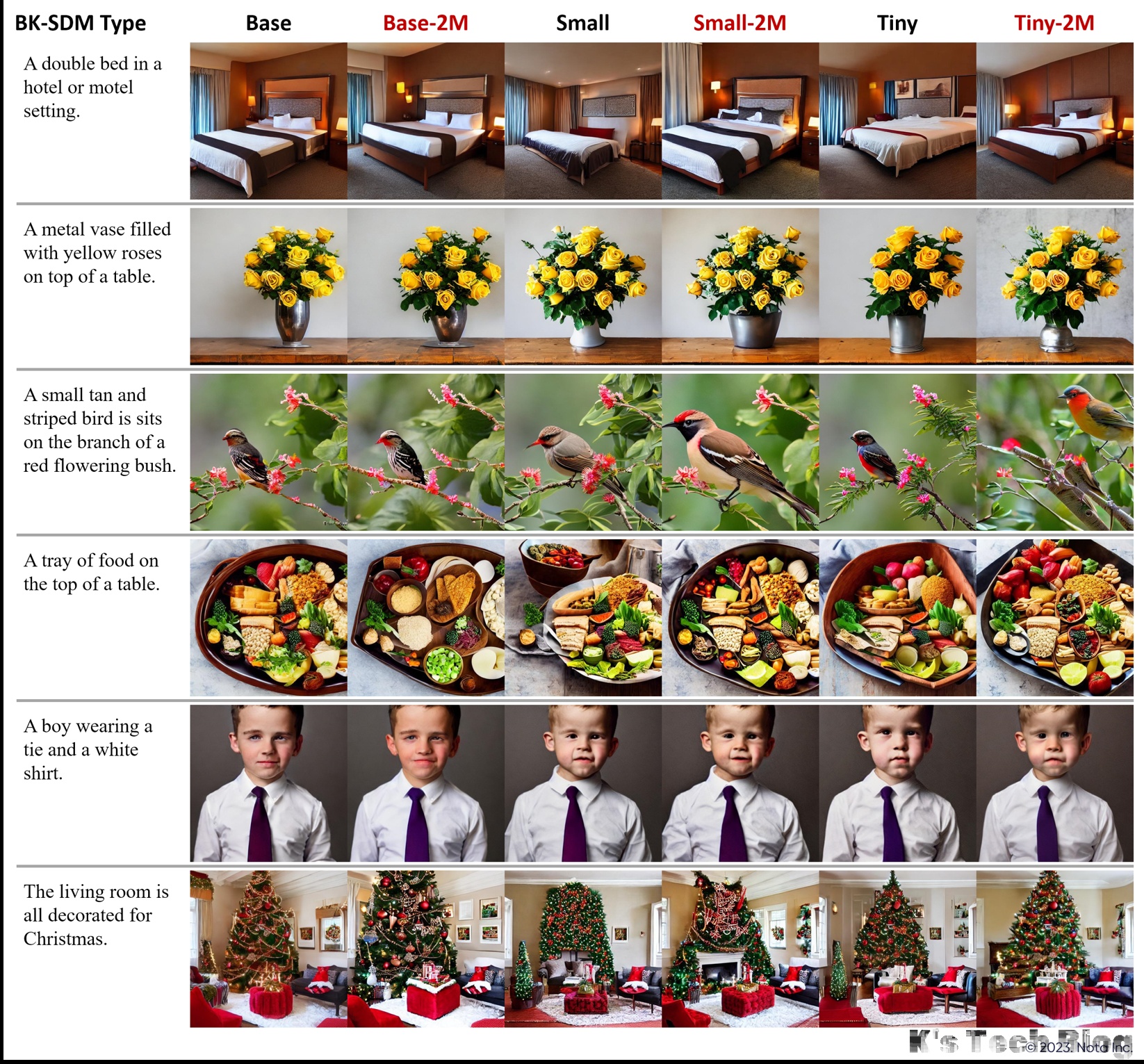
| The following figure depicts synthesized images with some MS-COCO captions. | |||||

|
Effect of Different Data Sizes for Training BK-SDM-Small
Increasing the number of training pairs improves the IS and CLIP scores over training progress. The MS-COCO 256×256 30K benchmark was used for evaluation.
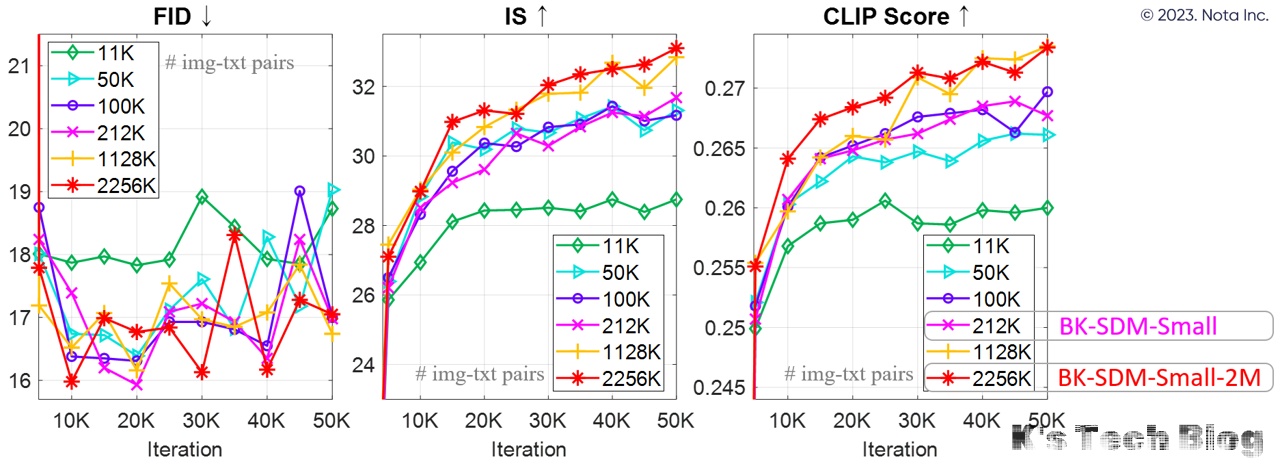 Furthermore, with the growth in data volume, visual results become more favorable (e.g., better image-text alignment and clear distinction among objects).
Furthermore, with the growth in data volume, visual results become more favorable (e.g., better image-text alignment and clear distinction among objects).
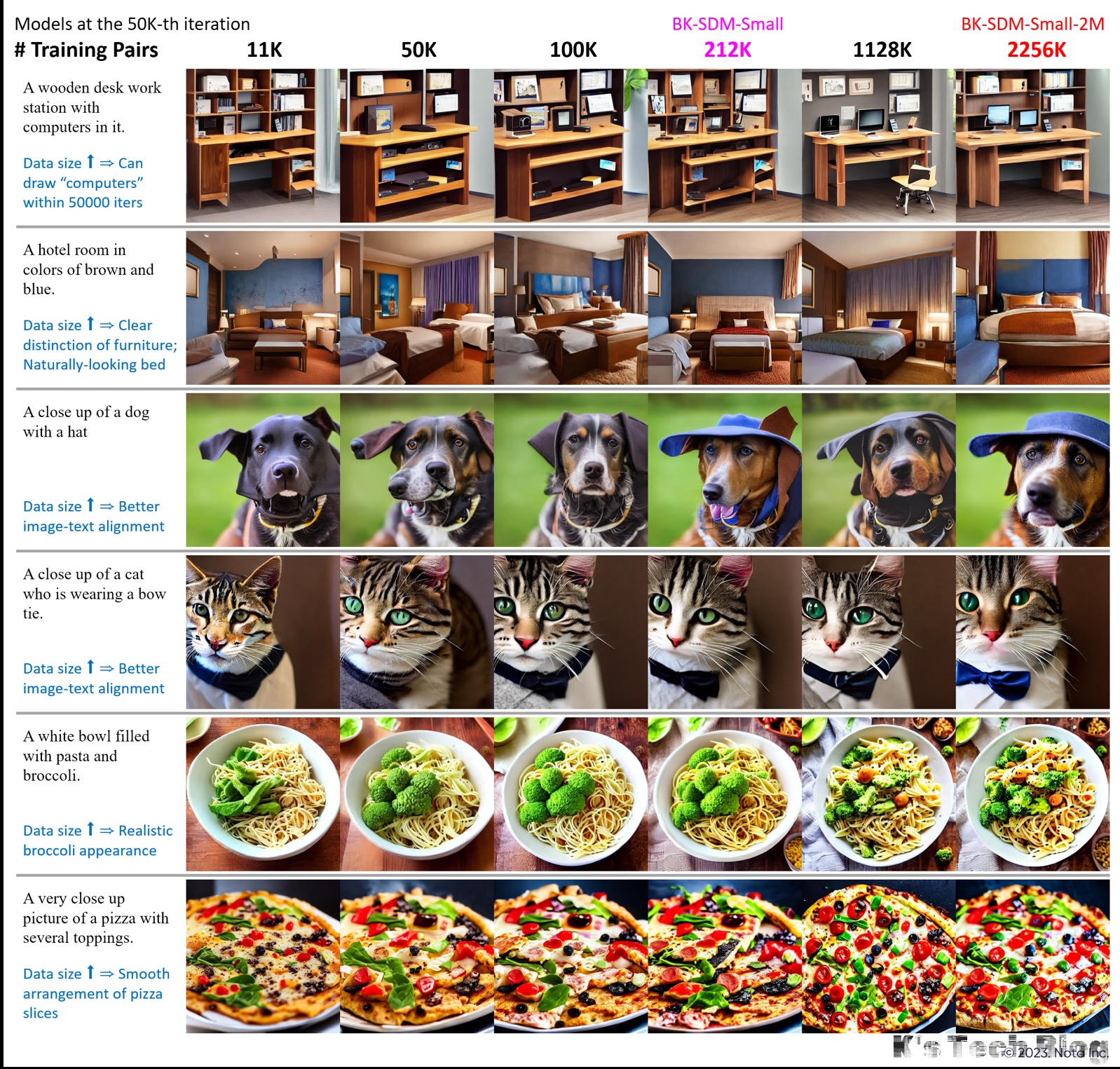
Additional Visual Examples
Personalized Generation (Full Finetuning)
To show the applicability of our lightweight SD backbones, we use DreamBooth finetuning for personalized generation.
- Each subject is marked as “a [identifier] [class noun]” (e.g., “a [V] dog”).
- Our BK-SDMs can synthesize the input subjects in different backgrounds while preserving their appearance.

底模SD1.5
segmind/tiny-sd
训练信息
code: segmind/distill-sd: Segmind Distilled diffusion (github.com)
- Base Model: SG161222/Realistic_Vision_V4.0_noVAE · Hugging Face
- Training Data
- Subset of recastai/LAION-art-EN-improved-captions dataset
- fantasyfish/laion-art(官方示例给的数据集)
- Steps: 125000
- Gradient Accumulations: 4
- Batch: 128 (=4×32)
- Mixed-precision: fp16
- Image resolution: 512
- Learning Rate: 1e-4
segmind/portrait-finetuned
大部分信息同segmind/tiny-sd,不过是在portrait images上面finetune过的模型。
训练信息
- Base Model: segmind/tiny-sd · Hugging Face
- Training Data
- 没细说,只说是portrait images,7k images
- Steps: 131000
- Gradient Accumulations: 4
- Batch: 128 (=4×32)
- Mixed-precision: fp16
- Image resolution: 768
- Learning Rate: 1e-4
测试信息汇总
| 模型 | FID-mscoco 30k | FID-mscoco 5k | Unet Params | Text Encoder Params | Image Decoder Parms | Whole Parms |
|---|---|---|---|---|---|---|
| runwayml/stable-diffusion-v1-5 | 13.8705 | 19.4507 | 0.860B | 0.123B | 0.05B | 1.032B |
| segmind/tiny-sd | 17.7266 | 23.0478 | 0.323B | 0.123B | 0.05B | 0.495B |
| tiny-sd-lcm-6400 | 22.1493 | 27.4531 | 0.323B | 0.123B | 0.05B | 0.495B |