监控&告警
Prometheus Operator
https://prometheus-operator.dev/ prometheus是被设计用来监控和告警单一集群性能问题的,如果要做多集群监控,可以看下面的Thanos
安装
kube-prometheus安装
# 使用kube-prometheus进行配置:https://github.com/prometheus-operator/kube-prometheus
# 拉取仓库
git clone https://github.com/prometheus-operator/kube-prometheus.git
# 切换分支
cd kube-prometheus
git checkout release-0.14
# Create the namespace and CRDs, and then wait for them to be available before creating the remaining resources
kubectl apply --server-side -f manifests/setup
# Wait until the "servicemonitors" CRD is created. The message "No resources found" means success in this context.
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl apply -f manifests/
# 卸载
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup外部访问
简单:通过端口映射的方式:
# Prometheus
kubectl --namespace monitoring port-forward svc/prometheus-k8s 9090 --address 0.0.0.0
# Grafana
kubectl --namespace monitoring port-forward svc/grafana 3000 --address 0.0.0.0
# Alertmanager
kubectl --namespace monitoring port-forward svc/alertmanager-main 9093 --address 0.0.0.0Ingress:通过ingress-nginx方式暴露服务出去。prometheus-operator配置了networkpolicies ,所以在配置ingress的时候需要一些额外的配置。先查看一下策略是什么kubectl get networkpolicies -n monitoring prometheus-main -o yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
creationTimestamp: "2025-02-06T10:38:21Z"
generation: 1
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 11.2.0
name: grafana
namespace: monitoring
resourceVersion: "6012143"
uid: 67650f19-0855-4c5c-9352-a4e0a0ab288c
spec:
egress:
- {}
ingress:
- from:
- podSelector:
matchLabels:
app.kubernetes.io/name: prometheus
ports:
- port: 3000
protocol: TCP
podSelector:
matchLabels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
policyTypes:
- Egress
- IngressPromQL语法基础
severity定义
常见的 severity 标签值:
critical:表示严重的告警,需要立即处理,通常意味着系统处于故障状态或严重异常。warning:表示警告级别的告警,虽然不紧急,但需要注意,可能预示着潜在的问题。info:表示信息级别的告警,通常用于提供关于系统状态的非紧急通知或日志。debug:通常表示调试信息级别的告警,主要用于开发和调试阶段,帮助排查问题。none:表示没有设定告警级别,有时用于某些没有实际告警的场景。
查询节点信息
# 查询节点资源容量
kube_node_status_capacity{node="faceunity", resource="faceunity_com_gpu"}
# 查询节点已申请的资源
kube_node_status_allocatable{node="faceunity", resource="faceunity_com_gpu"}Prometheus配置
ServiceMonitor 是 Prometheus Operator 用于定义如何发现和监控服务的自定义资源。
自定义监控指标
~~以自定义gpu指标为例子,~~这个例子不太好,因为指标已经通过ServiceMonitorkube-state-metrics暴露给prometheus了。后续有别的监控需求,在进行补充。
自定义报警rule
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node-gpu-rules
namespace: monitoring
# 下面的lable很重要,用于prometheus发现该rules
labels:
prometheus: k8s
role: alert-rules
spec:
groups:
- name: node-gpu.rules
rules:
- alert: LowNodeGPUCapacity
expr: |
kube_node_status_capacity{resource="faceunity_com_gpu"} - kube_node_status_allocatable{resource="faceunity_com_gpu"} > 90
for: 1m
labels:
severity: critical
annotations:
summary: "[{{ $labels.node }}]:节点GPU资源使用超过90%"
description: "[{{ $labels.node }}]:节点GPU资源使用超过90%"执行kubectl apply -f node-gpu-rules.yaml之后,就可以在kubectl get PrometheusRule -n monitoring中看到了,并且去到Prometheus dashboard,在rules中也能看到了:
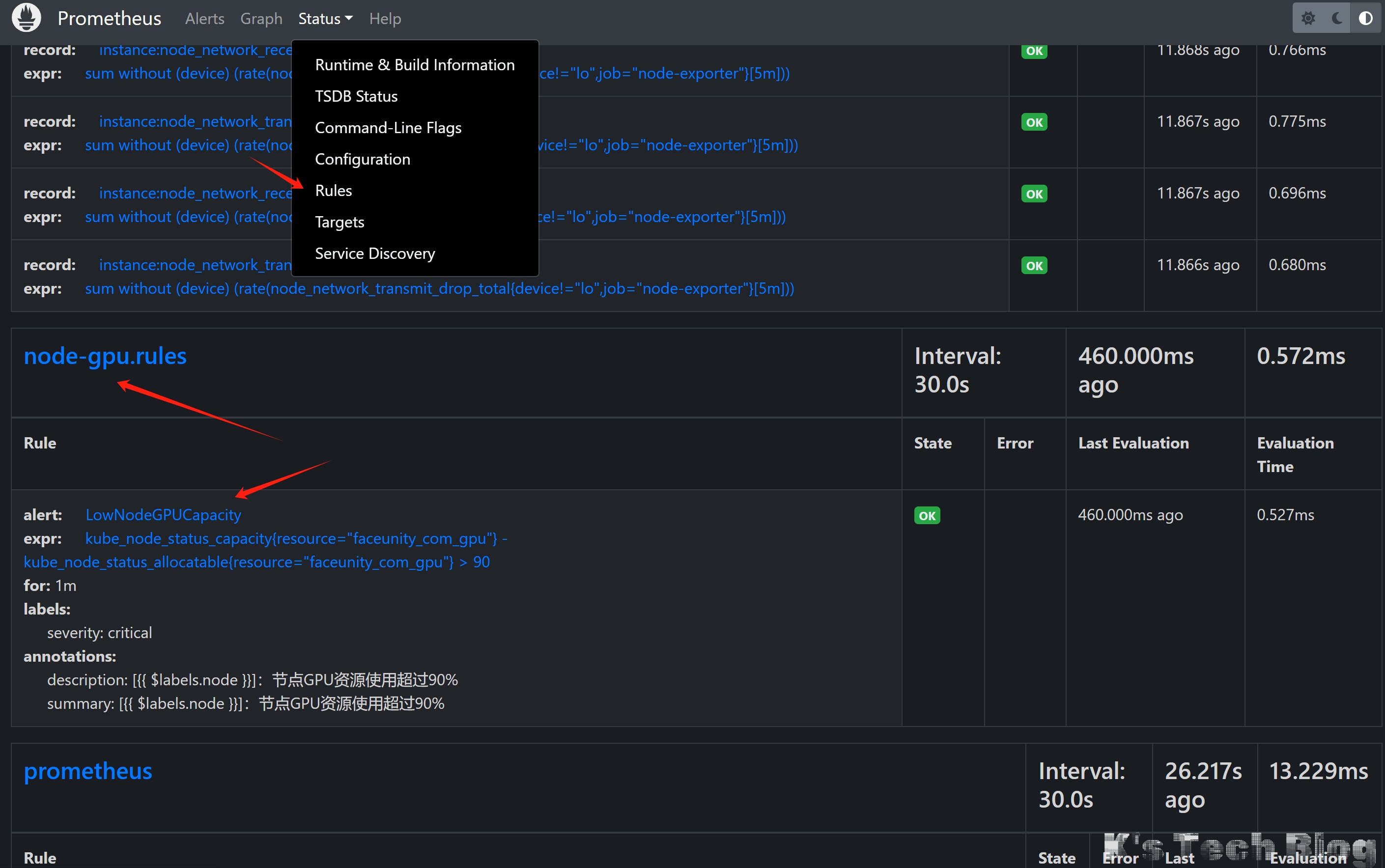
AlertManager配置
AlertManager在k8s中是一个CRD(Custom Resource Defination)可以通过kubectl get AlertManager -n monitoring看到,AlertManager的配置文件存储在Secret中,可以通过kubectl get Secret -n monitoring看到,是alertmanager-main,这个Secret中存储了alertmanager.yaml,我们要修改的就是这个Secret。
自定义通知
https://open.feishu.cn/open-apis/bot/v2/hook/448316ab-dba6-4f1e-ba85-37b5cd1c4032 以飞书通知为例,因为飞书的webhook传参需要特定格式,alertmanager的webhook不一致见,所以需要自定义一个webhook服务,将alertmanager的数据转发回飞书,这里使用开源项目alertmanager-webhook-feishu,作者也提供了helm安装方式,配置完成之后,就可以使用其进行转发了。
随后配置alertmanager,创建alert manager.yaml配置文件:
global:
# 这个数值表示当alert解决之后5min之后,才会确认该alert已经解决了
resolve_timeout: 1m # 5m
# 定义触发告警抑制的源告警条件。
# 避免无关警告的触发,这个是从alertmanager-main的原始secret中获取的
inhibit_rules:
- source_matchers:
- severity="critical"
target_matchers:
- severity=~"warning|info"
equal:
- namespace
- alertname
- source_matchers:
- severity="warning"
target_matchers:
- severity="info"
equal:
- namespace
- alertname
- source_matchers:
- alertname="InfoInhibitor"
target_matchers:
- severity="info"
equal:
- namespace
# 告警路由,通过那个receiver发
route:
receiver: Default
group_by: ['alertname'] # 表示所有`alertname`标签相同的告警会被分到同一组中
group_wait: 10s # 10s
group_interval: 10s # 5m
repeat_interval: 1m # 3h, 重复发送告警的时间间隔。如果同一个告警在 repeat_interval(3h)时间内没有被解决,Alertmanager 会重复发送相同的告警。
continue: false # continue的作用是指示是否应该在匹配到当前路由规则后,继续将告警转发到其他的路由
routes:
- receiver: Watchdog
matchers:
- alertname="Watchdog"
continue: false
- receiver: "null"
matchers:
- alertname="InfoInhibitor"
continue: false
- receiver: Critical
matchers:
- severity="critical"
continue: false
receivers:
- name: Critical
webhook_configs:
- url: 'http://192.168.0.211:8000/hook/webhook'
send_resolved: true
- name: Watchdog
- name: Default
- name: "null"
templates: []随后更新Secret alertmanager-main:
# --from-file支持重命名,比如--from-file=<target-name>=<source-file-path>
# generic:通用类型,用于存储任意键值对数据。
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring更新完配置之后,通过调用Alertmanager的api重新加载配置:curl -X POST <alertmanager-host>:<alertmanager-port>/-/reload。
Grafana配置
grafana使用下来,发现就是可视化使用promql查询的数据的工具。
OpenTelemetry
相关概念
OpenTelemetry是一个开源项目,旨在统一和简化分布式系统中telemetry数据(包括指标、日志和trace) 的采集和管理,它是由CNCF(云原生计算基金会)维护的,是云原生生态系统中非常重要的一部分。 主要功能和目标:
- 统一的标准:
- 提供统一的API、SDK和工具,方便开发者轻松集成telemetry数据采集。
- 支持多种语言(如Java、Python、Go等)。
- 分布式追踪:
- 帮助跟踪请求在分布式系统中的流动路径,记录每个服务的调用链。
- 生成详细的调用链数据,用于排查性能瓶颈和故障。
- 指标采集:
- 收集系统和应用的性能指标(如CPU、内存使用率、请求延迟等)。
- 为监控和分析提供数据支持。
- 日志管理:
- 提供结构化的日志记录能力,方便后续分析和排查问题。
- 与生态系统集成:
- 支持将telemetry数据导出到多种存储和分析工具(如Prometheus等)。
OpenTracing协议
OpenTracing协议是一个标准化的分布式追踪协议,旨在帮助开发者和运维人员更好的立即和监控分布式系统的性能和行为。
核心概念
- 分布式追踪:
- 在分布式系统中,一个请求可能经过多个服务(如API服务、数据库、第三方API等),OpenTracing通过记录请求的调用链,帮助跟踪请求的路径和性能。
- 每个服务的调用都会生成一个"跨度"(Span),表示一个操作的开始和结束。
- 跨度(Span):
- 表示一个具体的操作,如HTTP请求、数据库查询等。
- 包含时间戳、操作名称、标签、日志等信息。
- 跟踪(Trace):
- 由多个跨度组成,表示一个完整的请求路径。
- 通过唯一的追踪ID(Trace ID)将所有相关的跨度关联起来。
- 传播上下文:
- 在分布式系统中,请求会在不同的服务之间传递,OpenTracing通过传播上下文(如Trace ID、Span ID)来确保每个服务都能记录到正确的调用链中。
实践
相关资料
OpenTelemetry后端:Jaeger,好像也是个可视化工具 这里以公司当前项目的阿里云集群中的微服务为例子:
- 阿里云端到端链路追踪最佳实践:https://help.aliyun.com/zh/opentelemetry/use-cases/alibaba-cloud-end-to-end-link-tracing-best-practices?spm=a2c4g.11186623.help-menu-90275.d_3_0.59b3dbb5tBh5on
- C++:https://help.aliyun.com/zh/arms/tracing-analysis/use-opentelemetry-to-report-csharp-application-data?spm=a2c4g.11186623.help-menu-34364.d_2_0_8_0.5fc032d0160WPZ
- 全栈可观测:https://help.aliyun.com/zh/sls/user-guide/full-stack-observability/?spm=5176.2020520112.console-base_help.dexternal.7a723efd1gRa70
- Trace
- 全栈监控
- 性能监控
- 用户体验监控
- 通过OpenTelemetry为Node.js Express应用埋点并上报链路数据_可观测链路 OpenTelemetry 版(OpenTelemetry)-阿里云帮助中心
- 自动监测SDK文档:@opentelemetry/auto-instrumentations-node - npm
配置方式
# 自动监控的包
npm install --save @opentelemetry/api
npm install --save @opentelemetry/auto-instrumentations-node
# 随后启动程序前设置环境变量
export OTEL_TRACES_EXPORTER="otlp"
# 内网路径:http://tracing-analysis-dc-sh-internal.aliyuncs.com/adapt_cxsbpntjwq@c39e3166bb6c7c7_cxsbpntjwq@53df7ad2afe8301/api/otlp/traces
# 外网路径:http://tracing-analysis-dc-sh.aliyuncs.com/adapt_cxsbpntjwq@c39e3166bb6c7c7_cxsbpntjwq@53df7ad2afe8301/api/otlp/traces
export OTEL_EXPORTER_OTLP_TRACES_ENDPOINT="http://tracing-analysis-dc-sh.aliyuncs.com/adapt_cxsbpntjwq@c39e3166bb6c7c7_cxsbpntjwq@53df7ad2afe8301/api/otlp/traces"
export OTEL_NODE_RESOURCE_DETECTORS="all"
export OTEL_SERVICE_NAME="pro-scheduler-dev"
export NODE_OPTIONS="--require @opentelemetry/auto-instrumentations-node/register"
# 然后启动程序即可自动进行监控添加hook函数支持websocket监控
// websocket server端
import { Logger, Res, UseFilters, UseInterceptors } from "@nestjs/common";
import { MessageBody, SubscribeMessage, WebSocketGateway } from "@nestjs/websockets";
import { IResponse, ITask, ITaskInput, ITaskInputV2, ITaskResult, ITasks } from "../../common/Ihttp";
import { Response, ResponseCode } from "../../util/response";
import { DagTask } from "../../util/task";
import { ConnectionInterceptor, ConnectionPoolInstance, WsLocalStorage } from "../../util/ws";
import { SchedulerService } from '../service/scheduler.service';
import { DagTaskStatus, DagTask as _DagTask } from "../model/dagtask";
import { WSExceptionsFilter } from "../../util/logger";
import { TaskService } from "../service/task.service";
import { context, propagation, Span, trace, SpanKind } from '@opentelemetry/api';
import { SemanticAttributes } from "@opentelemetry/semantic-conventions";
const tracer = trace.getTracer("websocket-trace");
@UseInterceptors(ConnectionInterceptor)
@UseFilters(new WSExceptionsFilter())
@WebSocketGateway(Number(process.env['WS_PORT'] || 4000), { transports: ["websocket"] })
export class WSController {
private logger = new Logger(WSController.name);
constructor(
private readonly SchedulerService: SchedulerService,
private readonly TaskService: TaskService
) { }
/**
* 提交任务
*/
@SubscribeMessage("TaskSubmit")
public async TaskSubmit(
@MessageBody() task: ITaskInput
): Promise<IResponse<ITask>> {
// 提取otel的上下文
if (task.otel_context) {
const extractedContext = propagation.extract(
context.active(),
task.otel_context,
{
get: (carrier, key) => carrier[key],
keys: (carrier) => Object.keys(carrier),
}
);
// 创建一个新的 Span,用于表示 WebSocket 消息的接收
const span: Span = tracer.startSpan(`on:TaskSubmit`, {
kind: SpanKind.SERVER,
attributes: {
[SemanticAttributes.MESSAGING_SYSTEM]: "WebSocket.receive",
[SemanticAttributes.MESSAGING_DESTINATION]: "TaskSubmit",
},
}, extractedContext);
return await context.with(trace.setSpan(extractedContext, span), async () => {
this.logger.log(`提交任务:${task.queue}`);
this.logger.log(`任务:${JSON.stringify(task, null, 4)}`);
let taskid = "not created";
try {
const { queue, data } = task;
const dag = DagTask.deserialize(JSON.stringify(data));
this.logger.log(`任务解析完成`);
taskid = await this.SchedulerService.Submit(dag, queue);
const client = WsLocalStorage.getStore()?.client;
if (client) {
ConnectionPoolInstance.add(taskid, client);
}
this.logger.log(`任务提交完成`);
span.addEvent('Job submition complete.');
span.setAttribute("somethings", "test");
span.end();
return new Response(ResponseCode.Success, "成功", { taskid });
} catch(error) {
this.logger.error(`任务提交失败:${JSON.stringify(error)}`);
span.addEvent('Job submition failed!');
span.setAttribute("somethings", "test failed");
span.end();
return new Response(ResponseCode.Success, "成功", { taskid });
}
});
} else {
this.logger.log(`提交任务:${task.queue}`);
this.logger.log(`任务:${JSON.stringify(task, null, 4)}`);
const { queue, data } = task;
const dag = DagTask.deserialize(JSON.stringify(data));
this.logger.log(`任务解析完成`);
const taskid = await this.SchedulerService.Submit(dag, queue);
const client = WsLocalStorage.getStore()?.client;
if (client) {
ConnectionPoolInstance.add(taskid, client);
}
this.logger.log(`任务提交完成`);
return new Response(ResponseCode.Success, "成功", { taskid });
}
}
}import { io, Socket } from "socket.io-client";
import { context, trace, Span, SpanKind, propagation } from "@opentelemetry/api";
import { W3CTraceContextPropagator } from "@opentelemetry/core";
import { SemanticAttributes } from "@opentelemetry/semantic-conventions";
// 创建 OpenTelemetry 追踪器(tracer)
const tracer = trace.getTracer("websocket-trace");
const propagator = new W3CTraceContextPropagator();
/**
* 创建带 OpenTelemetry 追踪的 WebSocket 客户端
* @param url WebSocket 服务器地址
* @param options 连接选项
* @returns Hook 过的 WebSocket 客户端
*/
export function createTracedSocket(url: string, options?: any): Socket {
// 1️⃣ 创建 WebSocket 连接
const socket = io(url, options);
// 2️⃣ Hook `emit` 方法(拦截 WebSocket 发送消息)
const originalEmit = socket.emit; // 保存原始 emit 方法
socket.emit = function (event: string, ...args: any[]) {
return context.with(
trace.setSpan(context.active(), tracer.startSpan(`emit:${event}`, {
kind: SpanKind.CLIENT, // 代表客户端发送的请求
attributes: {
[SemanticAttributes.MESSAGING_SYSTEM]: "WebSocket.send",
[SemanticAttributes.MESSAGING_DESTINATION]: event,
},
})),
() => {
const currentContext = context.active();
const span = trace.getSpan(currentContext) as Span;
span?.setAttribute("event.data", JSON.stringify(args)); // 记录发送的数据
// 创建一个 carrier 对象,用于携带 OTEL 上下文
const carrier: { [key: string]: string } = {};
// 将当前上下文注入到 carrier 对象中
propagation.inject(currentContext, carrier, {
set: (carrier, key, value) => {
carrier[key] = value;
},
});
args[0] = {
...args[0],
otel_context: carrier
}
span?.end(); // 结束 Span
return originalEmit.apply(socket, [event, ...args]); // 调用原始 emit 方法
}
);
};
// 3️⃣ Hook `on` 方法(拦截 WebSocket 接收消息)
const originalOn = socket.on; // 保存原始 on 方法
socket.on = function (event: string, callback: (...args: any[]) => void) {
return originalOn.call(socket, event, (...args: any[]) => {
context.with(
trace.setSpan(context.active(), tracer.startSpan(`on:${event}`, {
kind: SpanKind.SERVER, // 代表服务器端返回的事件
attributes: {
[SemanticAttributes.MESSAGING_SYSTEM]: "WebSocket",
[SemanticAttributes.MESSAGING_DESTINATION]: event,
},
})),
() => {
const span = trace.getSpan(context.active()) as Span;
span?.setAttribute("event.data", JSON.stringify(args)); // 记录接收到的数据
callback(...args); // 执行原始回调
span?.end(); // 结束 Span
}
);
});
};
return socket;
}