Native编程
DMA-BUF
libdmabufheap.so 这个库是由Google开发的,和DMA(Direct Memory Access)缓冲区管理相关的库,通常用于处理Android系统中共享内存的分配和管理。这个库在图形处理、视频编解码、相机处理等需要高效内存管理和快速数据传输的场景中尤为重要。 DMA-BUF官方文档
具体来说libdmabufheap.so的主要功能包括:
- DMA缓存区分配:提供高效的内存分配机制,用于分配适合DMA操作的内存缓冲区。这些缓冲区可以在设备的不同硬件(ISP、CPU、GPU、DSP、显示控制器)之间共享和传输数据。
- 内存共享:在不同硬件组件和进程之间共享内存,避免数据拷贝,从而提高性能和降低延迟。例如、在相机应用中,捕获的图像数据可以直接传输到GPU进行处理和显示,而不需要额外的拷贝操作。
- 缓冲区管理:管理DMA缓存区的生命周期,包括分配、释放和回收等操作,确保内存资源的高效利用和系统的稳定性。
- 跨设备兼容性:提供了一种标准化的接口是的不同设备和硬件组件能够一致地使用DMA缓冲区,从而简化开发和维护工作。
DMA-BUF堆的概念
每个DMA-BUF堆都是一个位于/dev/dma_heap/<heap_name>的字符设备。
DMA-BUF 堆不支持堆专用标志。每种不同的分配都是在不同的堆中完成的。例如,缓存和未缓存的系统堆变体是位于 /dev/dma_heap/system 和 /dev/dma_heap/system_uncached 的独立堆。且堆名称用于分配。

个人理解
每个dma buffer在C++中存在形式就是一个文件描述符buf_fd,释放也很简单close(buf_fd)。但并不是一个独立的字符设备。
Linux中有万物皆文件的概念。
同时在操作map到当前设备的指针之前和之后,需要对设备进行同步,以保证dma buffer ready,eg:
#include <linux/dma-buf.h>
dma_buf_sync sync;
sync.flags = DMA_BUF_SYNC_END | DMA_BUF_SYNC_READ; //
ioctl(_record.buf_fd, DMA_BUF_IOCTL_SYNC, &sync)相关实现
Hexagon Halide实现
Hexagon-SDK/tools/HALIDE_Tools/2.5.02/Halide/Examples/standalone/device/utils/ion/ion_allocation.cpp中有ion/DMA buffer的相关实现,这里我直接抄过来了。
/* ==================================================================================== */
/* Copyright (c) 2016-2022 QUALCOMM Technologies, Inc. and/or its subsidiaries. */
/* All Rights Reserved. */
/* QUALCOMM Confidential and Proprietary */
/* ==================================================================================== */
#ifndef ION_ALLOCATION_H
#define ION_ALLOCATION_H
#ifdef __ANDROID__
#include <android/log.h>
#else
#include <log.h>
#include <stdint.h>
#endif
#include <dlfcn.h>
#include <fcntl.h>
#include <pthread.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <unistd.h>
void alloc_init();
void alloc_finalize();
void *alloc_ion(size_t size);
void alloc_ion_free(void *ptr);
#endif/* ==================================================================================== */
/* Copyright (c) 2016-2022 QUALCOMM Technologies, Inc. and/or its subsidiaries. */
/* All Rights Reserved. */
/* QUALCOMM Confidential and Proprietary */
/* ==================================================================================== */
#include "ion_allocation.h"
bool use_libdmabuf = false;
bool use_newer_ioctl = false;
bool use_libion = false;
namespace {
// DMA-BUF support
void *dmabufAllocator = nullptr;
extern "C" {
const char *dmabuf_heap = "system";
__attribute__((weak)) extern void *CreateDmabufHeapBufferAllocator();
typedef void * (*rem_dmabuf_create_fn)();
rem_dmabuf_create_fn dmabuf_create_fn = nullptr;
__attribute__((weak)) extern int DmabufHeapAlloc(void *buffer_allocator, const char *heap_name, size_t len, unsigned int heap_flags, size_t legacy_align);
typedef int (*rem_dmabuf_alloc_fn)(void *, const char *, size_t, unsigned int, size_t);
rem_dmabuf_alloc_fn dmabuf_alloc_fn = nullptr;
__attribute__((weak)) extern void FreeDmabufHeapBufferAllocator(void *buffer_allocator);
typedef void (*rem_dmabuf_deinit_fn)(void *);
rem_dmabuf_deinit_fn dmabuf_deinit_fn = nullptr;
}
// ION support
// Allocations that are intended to be shared with Hexagon can be
// shared without copying if they are contiguous in physical
// memory. Android's ION allocator gives us a mechanism with which we
// can allocate contiguous physical memory.
enum ion_heap_id {
system_heap_id = 25,
};
enum ion_flags {
ion_flag_cached = 1,
};
typedef int ion_user_handle_t;
struct ion_allocation_data {
size_t len;
size_t align;
unsigned int heap_id_mask;
unsigned int flags;
ion_user_handle_t handle;
};
struct ion_allocation_data_newer {
uint64_t len;
uint32_t heap_id_mask;
uint32_t flags;
uint32_t fd;
uint32_t unused;
};
struct ion_fd_data {
ion_user_handle_t handle;
int fd;
};
struct ion_handle_data {
ion_user_handle_t handle;
};
#define ION_IOC_ALLOC _IOWR('I', 0, ion_allocation_data)
#define ION_IOC_ALLOC_NEWER _IOWR('I', 0, ion_allocation_data_newer)
#define ION_IOC_FREE _IOWR('I', 1, ion_handle_data)
#define ION_IOC_MAP _IOWR('I', 2, ion_fd_data)
extern "C" {
__attribute__((weak)) extern int ion_open();
typedef int (*rem_ion_open_fn)();
rem_ion_open_fn ion_open_fn = nullptr;
__attribute__((weak)) extern int ion_alloc_fd(int ion_fd, size_t len, size_t align, unsigned int heap_id_mask, unsigned int flags, int *map_fd);
typedef int (*rem_ion_alloc_fd_fn)(int ion_fd, size_t len, size_t align, unsigned int heap_id_mask, unsigned int flags, int *map_fd);
rem_ion_alloc_fd_fn ion_alloc_fd_fn = nullptr;
}
// ION IOCTL approach
// This function will first try older IOCTL approach provided we have not determined
// that we should use the newer IOCTL. Once we have determined we should use the
// newer IOCTL method , we cease calling the older IOCTL.
ion_user_handle_t ion_alloc(int ion_fd, size_t len, size_t align, unsigned int heap_id_mask, unsigned int flags) {
if (use_libion) {
int map_fd = 0;
__android_log_print(ANDROID_LOG_INFO, "halide_test", "host_malloc: Using_libion");
if (ion_alloc_fd_fn(ion_fd, len, 0, heap_id_mask, flags, &map_fd)) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "ion_alloc: ion_alloc failed");
return -1;
}
__android_log_print(ANDROID_LOG_INFO, "halide_test", "ion_alloc: ion_alloc succeeded");
return map_fd;
}
if (!use_newer_ioctl) {
ion_allocation_data alloc = {
len,
align,
heap_id_mask,
flags,
0};
if (ioctl(ion_fd, ION_IOC_ALLOC, &alloc) >= 0) {
return alloc.handle;
}
}
// Lets try newer ioctl API
ion_allocation_data_newer alloc_newer = {
len,
heap_id_mask,
flags,
0,
0};
if (ioctl(ion_fd, ION_IOC_ALLOC_NEWER, &alloc_newer) >= 0) {
use_newer_ioctl = true;
return alloc_newer.fd;
}
// Abject failure
__android_log_print(ANDROID_LOG_INFO, "halide_test", "ion_alloc: Abject failure\n");
return -1;
}
int ion_map(int ion_fd, ion_user_handle_t handle) {
if (use_libion) {
return 0;
}
// old ioctl approach
ion_fd_data data = {
handle,
0};
if (ioctl(ion_fd, ION_IOC_MAP, &data) < 0) {
return -1;
}
return data.fd;
}
int ion_free(int ion_fd, ion_user_handle_t ion_handle) {
if (!use_libion) {
// We need to use this approach only if we are not using
// libion. If we are using libion (use_libion == true),
// then simply closing the fd (buf_fd) is enough. See
// alloc_ion_free below
if (ioctl(ion_fd, ION_IOC_FREE, &ion_handle) < 0) {
return -1;
}
}
return 0;
}
// We need to be able to keep track of the size and some other
// information about ION allocations, so define a simple linked list
// of allocations we can traverse later.
struct allocation_record {
allocation_record *next;
ion_user_handle_t handle;
int buf_fd;
void *buf;
size_t size;
};
// Make a dummy allocation so we don't need a special case for the
// head list node.
allocation_record allocations = {
nullptr,
};
pthread_mutex_t allocations_mutex = PTHREAD_MUTEX_INITIALIZER;
int ion_fd = -1;
} // namespace
extern "C" {
// If this symbol is defined in the stub library we are going to link
// to, we need to call this in order to actually get zero copy
// behavior from our buffers.
__attribute__((weak)) void remote_register_buf(void *buf, int size, int fd);
} // extern "C"
void alloc_init() {
if (ion_fd != -1) {
return;
}
if (dmabufAllocator != nullptr) {
return;
}
__android_log_print(ANDROID_LOG_INFO, "halide_test", "alloc_init: In alloc_init");
pthread_mutex_init(&allocations_mutex, nullptr);
use_libdmabuf = false;
use_newer_ioctl = false;
use_libion = false;
void* lib = nullptr;
// Try to access libdmabufheap.so, if it succeeds use DMA-BUF
lib = dlopen("libdmabufheap.so", RTLD_LAZY);
if (lib) {
use_libdmabuf = true;
dmabuf_create_fn = (rem_dmabuf_create_fn) dlsym(lib, "CreateDmabufHeapBufferAllocator");
dmabuf_deinit_fn = (rem_dmabuf_deinit_fn) dlsym(lib, "FreeDmabufHeapBufferAllocator");
dmabuf_alloc_fn = (rem_dmabuf_alloc_fn) dlsym(lib, "DmabufHeapAlloc");
if (!dmabuf_create_fn || !dmabuf_deinit_fn || !dmabuf_alloc_fn) {
__android_log_print(ANDROID_LOG_ERROR, "halide", "huge problem in libdmabufheap.so");
return;
}
dmabufAllocator = dmabuf_create_fn();
if (!dmabufAllocator) {
__android_log_print(ANDROID_LOG_ERROR, "halide", "dmabuf init failed");
return;
}
__android_log_print(ANDROID_LOG_INFO, "halide_test",
"alloc_init: using dmabuf. Finished.");
return;
}
// Try to access libion.so, if it succeeds use new approach
lib = dlopen("libion.so", RTLD_LAZY);
if (lib) {
use_libion = true;
ion_open_fn = (rem_ion_open_fn) dlsym(lib, "ion_open");
ion_alloc_fd_fn = (rem_ion_alloc_fd_fn) dlsym(lib, "ion_alloc_fd");
__android_log_print(ANDROID_LOG_INFO, "halide_test", "alloc_init: libion exists. use_libion=true");
if (!ion_open_fn || !ion_alloc_fd_fn) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_init: huge problem in libion.so");
return;
}
ion_fd = ion_open_fn();
if (ion_fd < 0) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_init: ion_open failed");
}
__android_log_print(ANDROID_LOG_INFO, "halide_test",
"alloc_init: using libion. Finished.");
} else {
ion_fd = open("/dev/ion", O_RDONLY, 0);
if (ion_fd < 0) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_init: open('/dev/ion') failed");
} else {
__android_log_print(ANDROID_LOG_INFO, "halide_test",
"alloc_init: Not using libion. Finished.");
}
}
}
void alloc_finalize() {
if (use_libdmabuf) {
if (dmabufAllocator == nullptr) {
return;
}
__android_log_print(ANDROID_LOG_INFO, "halide", "entering halide_hexagon_host_malloc_deinit dmabuf");
dmabuf_deinit_fn(dmabufAllocator);
dmabufAllocator = nullptr;
} else {
if (ion_fd == -1) {
return;
}
__android_log_print(ANDROID_LOG_INFO, "halide", "entering halide_hexagon_host_malloc_deinit ion");
close(ion_fd);
ion_fd = -1;
}
pthread_mutex_destroy(&allocations_mutex);
}
void *alloc_ion(size_t size) {
const int heap_id = system_heap_id;
const int ion_flags = ion_flag_cached;
// Hexagon can only access a small number of mappings of these
// sizes. We reduce the number of mappings required by aligning
// large allocations to these sizes.
static const size_t alignments[] = {0x1000, 0x4000, 0x10000, 0x40000, 0x100000};
size_t alignment = alignments[0];
// Align the size up to the minimum alignment.
size = (size + alignment - 1) & ~(alignment - 1);
if (heap_id != system_heap_id) {
for (size_t i = 0; i < sizeof(alignments) / sizeof(alignments[0]); i++) {
if (size >= alignments[i]) {
alignment = alignments[i];
}
}
}
int buf_fd = 0;
ion_user_handle_t handle = 0;
if (use_libdmabuf) {
buf_fd = dmabuf_alloc_fn(dmabufAllocator, dmabuf_heap, size, 0, 0);
if (buf_fd < 0) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_ion: DmabufHeapAlloc(%p, \"%s\", %zd, %d, %d) failed",
dmabufAllocator, dmabuf_heap, size, 0, 0);
return nullptr;
}
} else if (use_libion) {
buf_fd = ion_alloc(ion_fd, size, alignment, 1 << heap_id, ion_flags);
if (buf_fd < 0) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_ion: ion_alloc(%d, %zd, %zd, %d, %d) failed",
ion_fd, size, alignment, 1 << heap_id, ion_flags);
return nullptr;
}
} else { // !use_libion
handle = ion_alloc(ion_fd, size, alignment, 1 << heap_id, ion_flags);
if (handle < 0) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_ion: ion_alloc(%d, %zd, %zd, %d, %d) failed. use_libion=false",
ion_fd, size, alignment, 1 << heap_id, ion_flags);
return nullptr;
}
// Map the ion handle to a file buffer.
if (use_newer_ioctl) {
buf_fd = handle;
} else {
buf_fd = ion_map(ion_fd, handle);
if (buf_fd < 0) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_ion: ion_map(%d, %d) failed", ion_fd, handle);
ion_free(ion_fd, handle);
return nullptr;
}
}
}
// Map the file buffer to a pointer.
void *buf = mmap(nullptr, size, PROT_READ | PROT_WRITE, MAP_SHARED, buf_fd, 0);
if (buf == MAP_FAILED) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_ion: mmap(nullptr, %llu, PROT_READ | PROT_WRITE, MAP_SHARED, %d, 0) failed",
(long long)size, buf_fd);
close(buf_fd);
if (!use_newer_ioctl) {
ion_free(ion_fd, handle);
}
return nullptr;
}
// Register the buffer, so we get zero copy.
if (remote_register_buf) {
remote_register_buf(buf, size, buf_fd);
}
// Build a record for this allocation.
allocation_record *rec = (allocation_record *)malloc(sizeof(allocation_record));
if (!rec) {
__android_log_print(ANDROID_LOG_ERROR, "halide_test", "alloc_ion: malloc for allocation record failed");
munmap(buf, size);
close(buf_fd);
if (!use_newer_ioctl) {
ion_free(ion_fd, handle);
}
return nullptr;
}
rec->next = nullptr;
rec->handle = handle;
rec->buf_fd = buf_fd;
rec->buf = buf;
rec->size = size;
// Insert this record into the list of allocations. Insert it at
// the front, since it's simpler, and most likely to be freed
// next.
pthread_mutex_lock(&allocations_mutex);
rec->next = allocations.next;
allocations.next = rec;
pthread_mutex_unlock(&allocations_mutex);
__android_log_print(ANDROID_LOG_INFO, "halide_test", "alloc_ion: alloc succeeded");
return buf;
}
void alloc_ion_free(void *ptr) {
if (!ptr) {
return;
}
// Find the record for this allocation and remove it from the list.
pthread_mutex_lock(&allocations_mutex);
allocation_record *rec = &allocations;
while (rec) {
allocation_record *cur = rec;
rec = rec->next;
if (rec && rec->buf == ptr) {
cur->next = rec->next;
break;
}
}
pthread_mutex_unlock(&allocations_mutex);
if (!rec) {
__android_log_print(ANDROID_LOG_WARN, "halide_test", "alloc_ion_free: Allocation not found in allocation records");
return;
}
// Unregister the buffer.
if (remote_register_buf) {
remote_register_buf(rec->buf, rec->size, -1);
}
// Unmap the memory
munmap(rec->buf, rec->size);
// free the ION or DMA-BUF allocation
close(rec->buf_fd);
if (!use_libdmabuf && !use_libion && !use_newer_ioctl) {
// We free rec->handle only if we are not using libion and are
// also using the older ioctl. See alloc_ion above for more
// information.
if (ion_free(ion_fd, rec->handle) < 0) {
__android_log_print(ANDROID_LOG_WARN, "halide_test", "alloc_ion_free: ion_free(%d, %d) failed", ion_fd, rec->handle);
}
}
free(rec);
}CPP实现
我是用CPP修改之后的实现,删去了ION回退,只使用DMA Buffer。
#ifndef __OCLT_DMA_BUFFER_H__
#define __OCLT_DMA_BUFFER_H__
#include "oclt/common/context_manager.hpp"
#include <memory>
namespace oclt {
struct DMAAllocationRecord {
int buf_fd = -1;
size_t size = 0;
};
class DMABuffer {
public:
using Ptr = std::shared_ptr<DMABuffer>;
static Ptr Create(size_t size, size_t alignment = 0x1000,
const std::string &heap_name = "system");
static Ptr Create(int buf_fd, size_t size, bool is_owning);
~DMABuffer();
/*
* For data consistency, you need to use the buffer as follow, eg:
* ...
* if (!SyncBegin(SyncType::READ_ONLY)) {
* // Failed to sync, do somethings.
* return;
* }
* // Read the data by cpu pointer or cl_mem.
* ...
* if(!SyncEnd(SyncType::READ_ONLY)) {
* // Failed to sync, do somethings.
* return;
* }
* ...
*/
enum class SyncType { READ_ONLY = 0, WRITE_ONLY = 1, READ_WRITE = 2 };
bool SyncBegin(SyncType sync_type);
bool SyncEnd(SyncType sync_type);
// Map to cpu pointer.
void *GetCPUPtr();
// Map to cl_mem
// flags: CL_MEM_READ_ONLY, CL_MEM_WRITE_ONLY, CL_MEM_READ_WRITE
cl_mem GetCLMem(ctx::ContextManager::Ptr context, int flags);
// The create size.
size_t GetSize() const { return _size; }
// The aligned buffer size.
size_t GetRecordSize() const { return _record.size; }
private:
DMABuffer() = default;
void UnMapCPU();
void UnMapCL();
bool _is_owning = false;
DMAAllocationRecord _record;
void *_cpu_ptr = nullptr;
cl_mem _cl_mem = nullptr;
size_t _size = 0;
};
} // namespace oclt
#endif // __OCLT_DMA_BUFFER_H__
#include <iostream>
#include <mutex>
#include "oclt/common/dma_buffer.hpp"
#include "oclt/common/logging.hpp"
#if defined(__ANDROID__)
#include <dlfcn.h>
#include <fcntl.h>
#include <linux/dma-buf.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <unistd.h>
#endif
namespace oclt {
extern "C" {
// DMA Buffer function type.
__attribute__((weak)) extern void *CreateDmabufHeapBufferAllocator();
typedef void *(*rem_dmabuf_create_fn)();
__attribute__((weak)) extern int
DmabufHeapAlloc(void *buffer_allocator, const char *heap_name, size_t len,
unsigned int heap_flags, size_t legacy_align);
typedef int (*rem_dmabuf_alloc_fn)(void *, const char *, size_t, unsigned int,
size_t);
__attribute__((weak)) extern void
FreeDmabufHeapBufferAllocator(void *buffer_allocator);
typedef void (*rem_dmabuf_deinit_fn)(void *);
const char *dmabuflib_name = "libdmabufheap.so";
}
// Currently only implement DMABuffer for android
class DMABufferLib {
public:
using Ptr = std::shared_ptr<DMABufferLib>;
static Ptr GetInstance();
~DMABufferLib();
bool Alloc(size_t size, size_t alignment, const std::string &heap_name,
DMAAllocationRecord &record);
void Free(DMAAllocationRecord &record);
private:
DMABufferLib() = default;
bool Setup();
void Release();
static std::shared_ptr<DMABufferLib> _instance;
static std::mutex _mutex;
void *_lib = nullptr;
// DMA Buffer function.
void *_dmabuf_allocator = nullptr;
rem_dmabuf_create_fn _dmabuf_create_fn = nullptr;
rem_dmabuf_alloc_fn _dmabuf_alloc_fn = nullptr;
rem_dmabuf_deinit_fn _dmabuf_deinit_fn = nullptr;
};
// The release order is LIFO (not FIFO)
std::mutex DMABufferLib::_mutex;
DMABufferLib::Ptr DMABufferLib::_instance = nullptr;
DMABufferLib::Ptr DMABufferLib::GetInstance() {
#if defined(__ANDROID__)
if (_instance == nullptr) {
// Init the instance.
DMABufferLib::Ptr cur_instance = DMABufferLib::Ptr(new DMABufferLib);
if (cur_instance->Setup()) {
_instance = cur_instance;
}
}
return _instance;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return nullptr;
#endif
}
bool DMABufferLib::Setup() {
#if defined(__ANDROID__)
if (_dmabuf_allocator != nullptr) {
// Already inited.
return true;
}
SPDLOG_DEBUG("Setup allocator.");
std::lock_guard<std::mutex> lock(_mutex);
if (_lib == nullptr) {
// if lib is closed.
_lib = dlopen(dmabuflib_name, RTLD_LAZY);
}
if (_lib) {
SPDLOG_DEBUG("Setup dmabuf.");
_dmabuf_create_fn =
(rem_dmabuf_create_fn)dlsym(_lib, "CreateDmabufHeapBufferAllocator");
_dmabuf_deinit_fn =
(rem_dmabuf_deinit_fn)dlsym(_lib, "FreeDmabufHeapBufferAllocator");
_dmabuf_alloc_fn = (rem_dmabuf_alloc_fn)dlsym(_lib, "DmabufHeapAlloc");
if (!_dmabuf_create_fn || !_dmabuf_deinit_fn || !_dmabuf_alloc_fn) {
SPDLOG_ERROR("Failed to get function pointers from libdmabufheap.so");
return false;
}
_dmabuf_allocator = _dmabuf_create_fn();
if (!_dmabuf_allocator) {
SPDLOG_ERROR("Failed to init dmabuf.");
return false;
}
SPDLOG_DEBUG("Successfully setup dmabuf.");
return true;
} else {
SPDLOG_ERROR("Failed to open libdmabufheap.so.");
return false;
}
return true;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return false;
#endif
}
void DMABufferLib::Release() {
#if defined(__ANDROID__)
std::lock_guard<std::mutex> lock(_mutex);
if (_dmabuf_allocator) {
SPDLOG_DEBUG("Deinit dmabuf.");
_dmabuf_deinit_fn(_dmabuf_allocator);
_dmabuf_allocator = nullptr;
_dmabuf_create_fn = nullptr;
_dmabuf_deinit_fn = nullptr;
_dmabuf_alloc_fn = nullptr;
if (_lib) {
// close the lib
dlclose(_lib);
_lib = nullptr;
}
}
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return;
#endif
}
DMABufferLib::~DMABufferLib() { Release(); }
bool DMABufferLib::Alloc(size_t size, size_t alignment,
const std::string &heap_name,
DMAAllocationRecord &record) {
#if defined(__ANDROID__)
// Hexagon can only access a small number of mappings of these
// sizes. We reduce the number of mappings required by aligning
// large allocations to these sizes.
// const size_t alignments[] = {0x1000, 0x4000, 0x10000, 0x40000, 0x100000};
// size_t alignment = alignments[0];
// Align the size up to the minimum aligment.
size = (size + alignment - 1) & ~(alignment - 1);
int buf_fd = 0;
// const char *dmabuf_heap = "system"; // "qcom,system"
buf_fd = _dmabuf_alloc_fn(_dmabuf_allocator, heap_name.c_str(), size, 0, 0);
if (buf_fd < 0) {
SPDLOG_ERROR("DmabufHeapAlloc(\"{}\", {}, {}, {}) failed", heap_name, size,
0, 0);
return false;
}
record.buf_fd = buf_fd;
record.size = size;
SPDLOG_DEBUG("DMABufferLib::Alloc: alloc succeeded");
return true;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return false;
#endif
}
void DMABufferLib::Free(DMAAllocationRecord &record) {
#if defined(__ANDROID__)
// [ATTENTION]: This api must be called after unregister and unmaped.
// free the ION or DMA-BUF allocation
if (record.buf_fd >= 0) {
close(record.buf_fd);
// then reset it.
record.buf_fd = -1;
record.size = 0;
} else {
SPDLOG_WARN("DMABufferLib::Free: buf_fd is invalid, {}", record.buf_fd);
}
SPDLOG_DEBUG("DMABufferLib::Free: free buffer.");
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return;
#endif
}
DMABuffer::Ptr DMABuffer::Create(size_t size, size_t alignment,
const std::string &heap_name) {
#if defined(__ANDROID__)
DMABufferLib::Ptr dmabuf_lib = DMABufferLib::GetInstance();
if (!dmabuf_lib) {
SPDLOG_ERROR("DMABuffer::Create: Get dmabuf lib failed.");
return nullptr;
}
Ptr new_dma_buffer = DMABuffer::Ptr(new DMABuffer);
new_dma_buffer->_size = size;
new_dma_buffer->_is_owning = true;
if (dmabuf_lib->Alloc(size, alignment, heap_name, new_dma_buffer->_record)) {
return new_dma_buffer;
}
return nullptr;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return nullptr;
#endif
}
DMABuffer::Ptr DMABuffer::Create(int buf_fd, size_t size, bool is_owning) {
#if defined(__ANDROID__)
DMABufferLib::Ptr dmabuf_lib = DMABufferLib::GetInstance();
if (!dmabuf_lib) {
SPDLOG_ERROR("DMABuffer::Create: Get dmabuf lib failed.");
return nullptr;
}
if (buf_fd >= 0 && size >= 0) {
Ptr new_dma_buffer = DMABuffer::Ptr(new DMABuffer);
new_dma_buffer->_is_owning = is_owning;
new_dma_buffer->_size = size;
new_dma_buffer->_record.buf_fd = buf_fd;
new_dma_buffer->_record.size = size;
return new_dma_buffer;
} else {
SPDLOG_ERROR("DMABuffer's buf_fd({}) or size({}) is invalid.", buf_fd,
size);
return nullptr;
}
return nullptr;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return nullptr;
#endif
}
DMABuffer::~DMABuffer() {
#if defined(__ANDROID__)
// First unmap and unregister.
UnMapCL(); // CL need host ptr, so release is first.
UnMapCPU(); // Finally release the CPU memory.
// Then free the lib.
DMABufferLib::Ptr dmabuf_lib = DMABufferLib::GetInstance();
if (!dmabuf_lib) {
SPDLOG_ERROR("DMABuffer::~DMABuffer: Get dmabuf lib failed.");
return;
}
if (_is_owning) {
// own the dma buffer, so free it.
dmabuf_lib->Free(_record);
}
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return;
#endif
}
bool DMABuffer::SyncBegin(SyncType sync_type) {
#if defined(__ANDROID__)
dma_buf_sync sync;
sync.flags = DMA_BUF_SYNC_START;
if (SyncType::READ_ONLY == sync_type) {
// Read only.
sync.flags |= DMA_BUF_SYNC_READ;
} else if (SyncType::WRITE_ONLY == sync_type) {
// Write only.
sync.flags |= DMA_BUF_SYNC_WRITE;
} else {
// Read write.
sync.flags |= DMA_BUF_SYNC_RW;
}
if (ioctl(_record.buf_fd, DMA_BUF_IOCTL_SYNC, &sync)) {
SPDLOG_ERROR("Error preparing the cache for buffer process. The "
"DMA_BUF_IOCTL_SYNC operation returned {}",
strerror(errno));
return false;
} else {
SPDLOG_DEBUG("SyncBegin success.");
}
return true;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return false;
#endif
}
bool DMABuffer::SyncEnd(SyncType sync_type) {
#if defined(__ANDROID__)
dma_buf_sync sync;
sync.flags = DMA_BUF_SYNC_END;
if (SyncType::READ_ONLY == sync_type) {
// Read only.
sync.flags |= DMA_BUF_SYNC_READ;
} else if (SyncType::WRITE_ONLY == sync_type) {
// Write only.
sync.flags |= DMA_BUF_SYNC_WRITE;
} else {
// Read write.
sync.flags |= DMA_BUF_SYNC_RW;
}
if (ioctl(_record.buf_fd, DMA_BUF_IOCTL_SYNC, &sync)) {
SPDLOG_ERROR("Error preparing the cache for buffer process. The "
"DMA_BUF_IOCTL_SYNC operation returned {}",
strerror(errno));
return false;
} else {
SPDLOG_DEBUG("SyncEnd success.");
}
return true;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return false;
#endif
}
void *DMABuffer::GetCPUPtr() {
#if defined(__ANDROID__)
if (_cpu_ptr == nullptr) {
// Map the file buffer to a cpu pointer.
void *buf = mmap(nullptr, _record.size, PROT_READ | PROT_WRITE, MAP_SHARED,
_record.buf_fd, 0);
if (buf == MAP_FAILED) {
SPDLOG_ERROR("DMABuffer::GetCPUPtr: mmap(nullptr, {}, PROT_READ | "
"PROT_WRITE, MAP_SHARED, {}, 0) failed",
(long long)_record.size, _record.buf_fd);
return nullptr;
}
SPDLOG_DEBUG("DMABuffer::GetCPUPtr: mmaped cpu ptr");
_cpu_ptr = buf;
}
return _cpu_ptr;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return nullptr;
#endif
}
cl_mem DMABuffer::GetCLMem(ctx::ContextManager::Ptr context, int flags) {
#if defined(__ANDROID__)
// get host ptr first
if (_cl_mem != nullptr) {
return _cl_mem;
} else {
void *host_ptr = GetCPUPtr();
SPDLOG_DEBUG("DMABuffer::GetCLMem: mapping dma buffer to cl_mem.");
// use dma buffer
if (context->checkExtensionSupported("cl_qcom_dmabuf_host_ptr")) {
cl_mem_dmabuf_host_ptr dmabuf_config;
dmabuf_config.ext_host_ptr.allocation_type = CL_MEM_DMABUF_HOST_PTR_QCOM;
dmabuf_config.ext_host_ptr.host_cache_policy =
CL_MEM_HOST_IOCOHERENT_QCOM;
dmabuf_config.dmabuf_filedesc = _record.buf_fd;
dmabuf_config.dmabuf_hostptr = host_ptr;
cl_int errcode = 0;
flags = flags | CL_MEM_USE_HOST_PTR | CL_MEM_EXT_HOST_PTR_QCOM;
cl_mem buffer = clCreateBuffer(context->context().get(), flags,
_record.size, &dmabuf_config, &errcode);
if (errcode == CL_SUCCESS) {
_cl_mem = buffer;
}
SPDLOG_DEBUG("DMABuffer::GetCLMem: dma buffer map success.");
return _cl_mem;
}
}
return nullptr;
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return nullptr;
#endif
}
void DMABuffer::UnMapCPU() {
#if defined(__ANDROID__)
if (_cpu_ptr) {
// Unmap the cpu pointer.
SPDLOG_DEBUG("DMABuffer::UnMapCPU: unmaped cpu pointer.");
munmap(_cpu_ptr, _record.size);
_cpu_ptr = nullptr;
}
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return;
#endif
}
void DMABuffer::UnMapCL() {
#if defined(__ANDROID__)
if (_cl_mem) {
SPDLOG_DEBUG("DMABuffer::UnMapCL: unmaped cl_mem pointer.");
clReleaseMemObject(_cl_mem);
_cl_mem = nullptr;
}
#else
SPDLOG_ERROR("DMABuffer is only supported on Android Platform.");
return;
#endif
}
} // namespace oclt
#include <algorithm>
#include <chrono>
#include <fstream>
#include <iostream>
#include <memory>
#include <sstream>
#include <string>
#include "oclt/common/context_manager.hpp"
#include "oclt/common/dma_buffer.hpp"
#include "oclt/common/logging.hpp"
#include "oclt/common/timer.hpp"
#include "oclt/imgproc/math.hpp"
#include <opencv2/core.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
using namespace oclt;
#define TEST_NUM_CHANNEL 3
#define USE_DMABUF
oclt::imgproc::MAD::Ptr
getClKernel(oclt::ctx::ContextManager::Ptr context_manager) {
std::string kernelSource;
{
std::ifstream sourceFile("./assets/math.cl");
std::stringstream stream;
stream << sourceFile.rdbuf();
kernelSource = stream.str();
}
return imgproc::MAD::create(context_manager, {kernelSource});
}
int main() {
logging::setLogLevel(SPDLOG_LEVEL_INFO);
ctx::ContextManager::Ptr context_manager = ctx::ContextManager::create();
if (!ctx::ContextManager::checkOpenCLAvailable()) {
SPDLOG_ERROR("OpenCL is inavailable.");
return EXIT_FAILURE;
}
// Test opencv
cv::Mat image = cv::imread("./assets/test_image.jpg");
int width = image.cols;
int height = image.rows;
#if TEST_NUM_CHANNEL == 1
cv::cvtColor(image, image, cv::COLOR_BGR2GRAY);
#elif TEST_NUM_CHANNEL == 4
cv::cvtColor(image, image, cv::COLOR_BGR2BGRA);
#endif
const int channel = image.channels();
// First copy data into dma buffer.
const size_t image_data_size = width * height * channel * sizeof(uint8_t);
SPDLOG_INFO("Input image width: {}, height: {}, channels: {}", width, height,
channel);
STACK_TIMER_BEGIN(overall_time);
#ifdef USE_DMABUF
STACK_TIMER_BEGIN(dmabuf_create_source);
// Allocate the source buffer, and copy image into it.
DMABuffer::Ptr source_dmabuf_ptr =
DMABuffer::Create(image_data_size, 0x1000); // 默认使用4kB对齐
uint8_t *source_cpu_ptr =
reinterpret_cast<uint8_t *>(source_dmabuf_ptr->GetCPUPtr());
cl_mem source_gpu_ptr =
source_dmabuf_ptr->GetCLMem(context_manager, CL_MEM_READ_ONLY);
STACK_TIMER_END(dmabuf_create_source);
STACK_TIMER_BEGIN(dmabuf_copy_source);
if (!source_dmabuf_ptr->SyncBegin(DMABuffer::SyncType::WRITE_ONLY)) {
SPDLOG_ERROR("Begin sync for write error.");
return EXIT_FAILURE;
}
std::copy(image.data, image.data + image_data_size, source_cpu_ptr);
if (!source_dmabuf_ptr->SyncEnd(DMABuffer::SyncType::WRITE_ONLY)) {
SPDLOG_ERROR("End sync for write error.");
return EXIT_FAILURE;
}
STACK_TIMER_END(dmabuf_copy_source);
if (source_cpu_ptr == nullptr || source_gpu_ptr == nullptr) {
SPDLOG_ERROR("source dmabuf map to cpu or gpu failed");
return EXIT_FAILURE;
}
STACK_TIMER_BEGIN(dmabuf_create_result);
// Allocate the result buffer
DMABuffer::Ptr result_dmabuf_ptr = DMABuffer::Create(image_data_size, 0x1000);
uint8_t *result_cpu_ptr =
reinterpret_cast<uint8_t *>(result_dmabuf_ptr->GetCPUPtr());
cl_mem result_gpu_ptr =
result_dmabuf_ptr->GetCLMem(context_manager, CL_MEM_WRITE_ONLY);
if (result_cpu_ptr == nullptr || result_gpu_ptr == nullptr) {
SPDLOG_ERROR("result dmabuf map to cpu or gpu failed");
return EXIT_FAILURE;
}
STACK_TIMER_END(dmabuf_create_result);
#endif
// Get kernel
STACK_TIMER_BEGIN(load_cl_kernel);
auto mad = getClKernel(context_manager);
STACK_TIMER_END(load_cl_kernel);
#ifdef USE_DMABUF
STACK_TIMER_BEGIN(mad_run);
if (!result_dmabuf_ptr->SyncBegin(DMABuffer::SyncType::WRITE_ONLY)) {
SPDLOG_ERROR("End sync for write error.");
return EXIT_FAILURE;
}
mad->run(source_gpu_ptr, OCLT_8U, 1.5, 1, result_gpu_ptr, OCLT_8U, width,
height, channel);
if (!result_dmabuf_ptr->SyncEnd(DMABuffer::SyncType::WRITE_ONLY)) {
SPDLOG_ERROR("End sync for write error.");
return EXIT_FAILURE;
}
STACK_TIMER_END(mad_run);
STACK_TIMER_BEGIN(result_opencv_map);
if (!result_dmabuf_ptr->SyncBegin(DMABuffer::SyncType::READ_ONLY)) {
SPDLOG_ERROR("Begin sync for read error.");
return EXIT_FAILURE;
}
cv::Mat test_result_image(cv::Size(width, height), CV_8UC(channel),
result_cpu_ptr);
if (!result_dmabuf_ptr->SyncEnd(DMABuffer::SyncType::READ_ONLY)) {
SPDLOG_ERROR("End sync for read error.");
return EXIT_FAILURE;
}
STACK_TIMER_END(result_opencv_map);
#else
STACK_TIMER_BEGIN(create_cv_result)
cv::Mat test_result_image(cv::Size(width, height), CV_8UC(channel));
STACK_TIMER_END(create_cv_result)
STACK_TIMER_BEGIN(mad_run);
mad->run(image.ptr<uint8_t>(), 1.5, 1, test_result_image.ptr<uint8_t>(),
width, height, channel);
STACK_TIMER_END(mad_run);
#endif // USE_DMABUF
STACK_TIMER_END(overall_time);
cv::imwrite("result_image.jpg", test_result_image);
return EXIT_SUCCESS;
}AHardwareBuffer
样例工程: kaihang/HardwareBufferExample
AhardwareBuffer是Android平台引入的一种跨进程内存共享机制,主要用于高效处理图形数据。
上面的测试工程中关于AHardwareBuffer的使用介绍的非常全面。简而言之,android平台创建的ahardwarebuffer,可以很方便和快速的映射成:cpu pointer、cl_mem、EGLImage(for OpenGL texture)。
下层是GraphicBuffer,底层是通过gralloc来管理内存。
日志打印
#ifndef __LOGGING__
#define __LOGGING__
#include <android/log.h>
#define LOG_TAG "MemoryProfiler"
#define MY_LOGD(...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, __VA_ARGS__)
#define MY_LOGI(...) __android_log_print(ANDROID_LOG_INFO, LOG_TAG, __VA_ARGS__)
#define MY_LOGW(...) __android_log_print(ANDROID_LOG_WARN, LOG_TAG, __VA_ARGS__)
#define MY_LOGE(...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, __VA_ARGS__)
#endif // __LOGGING__
内存分析
AddressSanitizer
Malloc Hooks(无效)
Malloc hooks allows a program to intercept all allocation/free calls that happen during execution. It is only available in Android P and newer versions of the OS.
There are two ways to enable these hooks, set a special system property, or set a special environment variable and run your app/program.
When malloc hooks is enabled, it works by adding a shim layer that replaces the normal allocation calls. The replaced calls are:
mallocfreecallocreallocposix_memalignmemalignaligned_allocmalloc_usable_sizeOn 32 bit systems, these two deprecated functions are also replaced:pvallocvallocThese four hooks are defined in malloc.h:
void* (*volatile __malloc_hook)(size_t, const void*);
void* (*volatile __realloc_hook)(void*, size_t, const void*);
void (*volatile __free_hook)(void*, const void*);
void* (*volatile __memalign_hook)(size_t, size_t, const void*);When malloc is called and __malloc_hook has been set, then the hook function is called instead.
When realloc is called and __realloc_hook has been set, then the hook function is called instead.
When free is called and __free_hook has been set, then the hook function is called instead.
When memalign is called and __memalign_hook has been set, then the hook function is called instead.
For posix_memalign, if __memalign_hook has been set, then the hook is called, but only if alignment is a power of 2.
For aligned_alloc, if __memalign_hook has been set, then the hook is called, but only if alignment is a power of 2.
For calloc, if __malloc_hook has been set, then the hook function is called, then the allocated memory is set to zero.
For the two deprecated functions pvalloc and valloc, if __memalign_hook has been set, then the hook is called with an appropriate alignment value.
There is no hook for malloc_usable_size as of now.
These hooks can be set at any time, but there is no thread safety, so the caller must guarantee that it does not depend on allocations/frees occurring at the same time.
Implementation Details
When malloc hooks is enabled, then the hook pointers are set to the current default allocation functions. It is expected that if an app does intercept the allocation/free calls, it will eventually call the original hook function to do allocations. If the app does not do this, it runs the risk of crashing whenever a malloc_usable_size call is made.
Example Implementation
Below is a simple implementation intercepting only malloc/calloc calls.
void* new_malloc_hook(size_t bytes, const void* arg) {
return orig_malloc_hook(bytes, arg);
}
auto orig_malloc_hook = __malloc_hook;
__malloc_hook = new_malloc_hook;Enabling Examples
For platform developers
Enable the hooks for all processes:
# Require root.
adb shell stop
adb shell setprop libc.debug.hooks.enable 1
adb shell startEnable malloc hooks using an environment variable:
adb shell
# export LIBC_HOOKS_ENABLE=1
# lsAny process spawned from this shell will run with malloc hooks enabled.
For app developers
Enable malloc hooks for a specific program/application:
adb shell setprop wrap.<APP> '"LIBC_HOOKS_ENABLE=1"'For example, to enable malloc hooks for the google search box:
adb shell setprop wrap.com.google.android.googlequicksearchbox '"LIBC_HOOKS_ENABLE=1 logwrapper"'
adb shell am force-stop com.google.android.googlequicksearchboxNOTE: On pre-O versions of the Android OS, property names had a length limit of 32. This meant that to create a wrap property with the name of the app, it was necessary to truncate the name to fit. On O, property names can be an order of magnitude larger, so there should be no need to truncate the name at all.
simpleperf
好像能力有限
NDK和Android系统中已经包含了,可以直接使用
adb shell "simpleperf --help"record native程序:
# 直接record可执行程序
adb shell "cd /dir/to/your_exe && simpleperf record ./your_exe"perfetto
Android系统自带的工具,官方文档见:Perfetto Docs。
仓库地址: git@github.com:google/perfetto.git
日志抓取:adb logcat *:S perfetto:V可以在perfetto不work的时候抓一下看看问题是啥。
概念
schd:Linux内核中的调度事件,这两个事件对于线程切换、调度延迟和多线程应用的新能问题很重要
常用config
heapprofd
buffers {
size_kb: 63488
}
data_sources {
config {
name: "android.heapprofd"
heapprofd_config {
shmem_size_bytes: 8388608
sampling_interval_bytes: 4096
block_client: true
process_cmdline: "com.example.simplejniexample"
continuous_dump_config {
dump_phase_ms: 0
dump_interval_ms: 5000
}
}
}
}
duration_ms: 0
write_into_file: true
flush_timeout_ms: 30000
flush_period_ms: 604800000
data_sources {
config {
name: "android.packages_list"
}
}trace_event
这个就是常用的perfetto sdk抓取trace_event的方式,在代码中使用SystemBackend,并且写好TRACE_EVENT,随后使用perfetto指令
buffers: {
size_kb: 63488
fill_policy: DISCARD
}
data_sources {
config {
name: "track_event"
track_event_config {
enabled_categories: "camera_beauty"
disabled_categories: "*"
}
}
}
duration_ms: 30000
write_into_file: true
flush_timeout_ms: 10000
flush_period_ms: 604800000
data_sources {
config {
name: "android.packages_list"
}
}battery
buffers: {
size_kb: 63488
fill_policy: DISCARD
}
data_sources: {
config {
name: "android.power"
android_power_config {
battery_poll_ms: 250
collect_power_rails: true # 支持的手机不多,pixel6能跑,xiaomi12跑不了
# Note: it is possible to specify both rails and battery counters
# in this section.
# 下面这些都可以跑
battery_counters: BATTERY_COUNTER_CURRENT # 瞬时电流
battery_counters: BATTERY_COUNTER_VOLTAGE # 电压,会报错,不知道为什么
}
}
}
duration_ms: 30000
write_into_file: true
flush_timeout_ms: 10000
flush_period_ms: 604800000
data_sources {
config {
name: "android.packages_list"
}
}UI
README路径:perfetto/ui/README.md(编译、运行的方式)
命令行工具
# Needed only on Android 9 (P) and 10 (Q) on non-Pixel phones.
adb shell setprop persist.traced.enable 1
# Profile for trace
adb shell perfetto -o /data/misc/perfetto-traces/trace_file.perfetto-trace -t 20s \
sched freq idle am wm gfx view binder_driver hal dalvik camera input res memorySDK
代码路径:perfetto/sdk
Example
#include <chrono>
#include <fstream>
#include <thread>
#include <perfetto.h>
#include <unistd.h>
#include <fcntl.h>
// The set of track event categories that the example is using.
PERFETTO_DEFINE_CATEGORIES(
perfetto::Category("rendering")
.SetDescription("Rendering and graphics events"),
perfetto::Category("network.debug")
.SetTags("debug")
.SetDescription("Verbose network events"),
perfetto::Category("audio.latency")
.SetTags("verbose")
.SetDescription("Detailed audio latency metrics"));
PERFETTO_TRACK_EVENT_STATIC_STORAGE();
namespace {
void InitializePerfetto() {
perfetto::TracingInitArgs args;
// The backends determine where trace events are recorded. For this example we
// are going to use the in-process tracing service, which only includes in-app
// events.
args.backends = perfetto::kInProcessBackend;
perfetto::Tracing::Initialize(args);
perfetto::TrackEvent::Register();
}
std::unique_ptr<perfetto::TracingSession> StartTracing(int output_fd) {
// The trace config defines which types of data sources are enabled for
// recording. In this example we just need the "track_event" data source,
// which corresponds to the TRACE_EVENT trace points.
perfetto::TraceConfig cfg;
cfg.add_buffers()->set_size_kb(1024);
auto *ds_cfg = cfg.add_data_sources()->mutable_config();
ds_cfg->set_name("track_event");
auto tracing_session = perfetto::Tracing::NewTrace();
tracing_session->Setup(cfg, output_fd);
tracing_session->StartBlocking();
return tracing_session;
}
void StopTracing(std::unique_ptr<perfetto::TracingSession> tracing_session) {
// Make sure the last event is closed for this example.
perfetto::TrackEvent::Flush();
// Stop tracing and read the trace data.
tracing_session->StopBlocking();
// std::vector<char> trace_data(tracing_session->ReadTraceBlocking());
// Write the result into a file.
// Note: To save memory with longer traces, you can tell Perfetto to write
// directly into a file by passing a file descriptor into Setup() above.
// std::ofstream output;
// output.open("example.pftrace", std::ios::out | std::ios::binary);
// output.write(&trace_data[0], std::streamsize(trace_data.size()));
// output.close();
// PERFETTO_LOG("Trace written in example.pftrace file. To read this trace in "
// "text form, run `./tools/traceconv text example.pftrace`");
}
void DrawPlayer(int player_number) {
TRACE_EVENT("rendering", "DrawPlayer", "player_number", player_number);
// Sleep to simulate a long computation.
std::this_thread::sleep_for(std::chrono::milliseconds(500));
}
void DrawGame() {
// This is an example of an unscoped slice, which begins and ends at specific
// points (instead of at the end of the current block scope).
TRACE_EVENT_BEGIN("rendering", "DrawGame");
DrawPlayer(1);
DrawPlayer(2);
TRACE_EVENT_END("rendering");
// Record the rendering framerate as a counter sample.
// TRACE_COUNTER("rendering", "Framerate", 120);
}
} // namespace
int main(int, const char **) {
InitializePerfetto();
int output_fd = open("example.pftrace", O_RDWR | O_CREAT | O_TRUNC, 0666);
auto tracing_session = StartTracing(output_fd);
// Give a custom name for the traced process.
perfetto::ProcessTrack process_track = perfetto::ProcessTrack::Current();
perfetto::protos::gen::TrackDescriptor desc = process_track.Serialize();
desc.mutable_process()->set_process_name("Example");
perfetto::TrackEvent::SetTrackDescriptor(process_track, desc);
// Simulate some work that emits trace events.
DrawGame();
StopTracing(std::move(tracing_session));
close(output_fd);
return 0;
}使用案例
heap profile测试
- 参照Android Studio JNI,将要profile的库集成到一个简易的apk中,并且在
AndroidManifest.xml中配置profileable - 随后可以利用如下脚本进行heap profile,得到的结果在
RESULT_DIR中,-c的含义是每隔1000ms抓取一次;另外有些用户自己提供的库符号没法自动提取,可以使用第五行的traceconv手动填充符号
pushd $PERFETTO_ROOT &>/dev/null
# heap profile
./tools/heap_profile -n com.example.simplejniexample -o $RESULT_DIR -c 1000
# 离线填充fuai和CNamaSDK的符号
PERFETTO_BINARY_PATH=$LIB_DIR tools/traceconv symbolize $RESULT_DIR/raw-trace > $RESULT_DIR/symbols
# 合并trace
cat $RESULT_DIR/raw-trace $RESULT_DIR/symbols > $RESULT_DIR/symbolized-trace
popd &>/dev/null- 将trace拖入
ui中进行查看,以下是一个案例,其中红色小箭头是抓取时刻的unreleased malloc size,下面就是详细的内存数量和申请堆栈信息;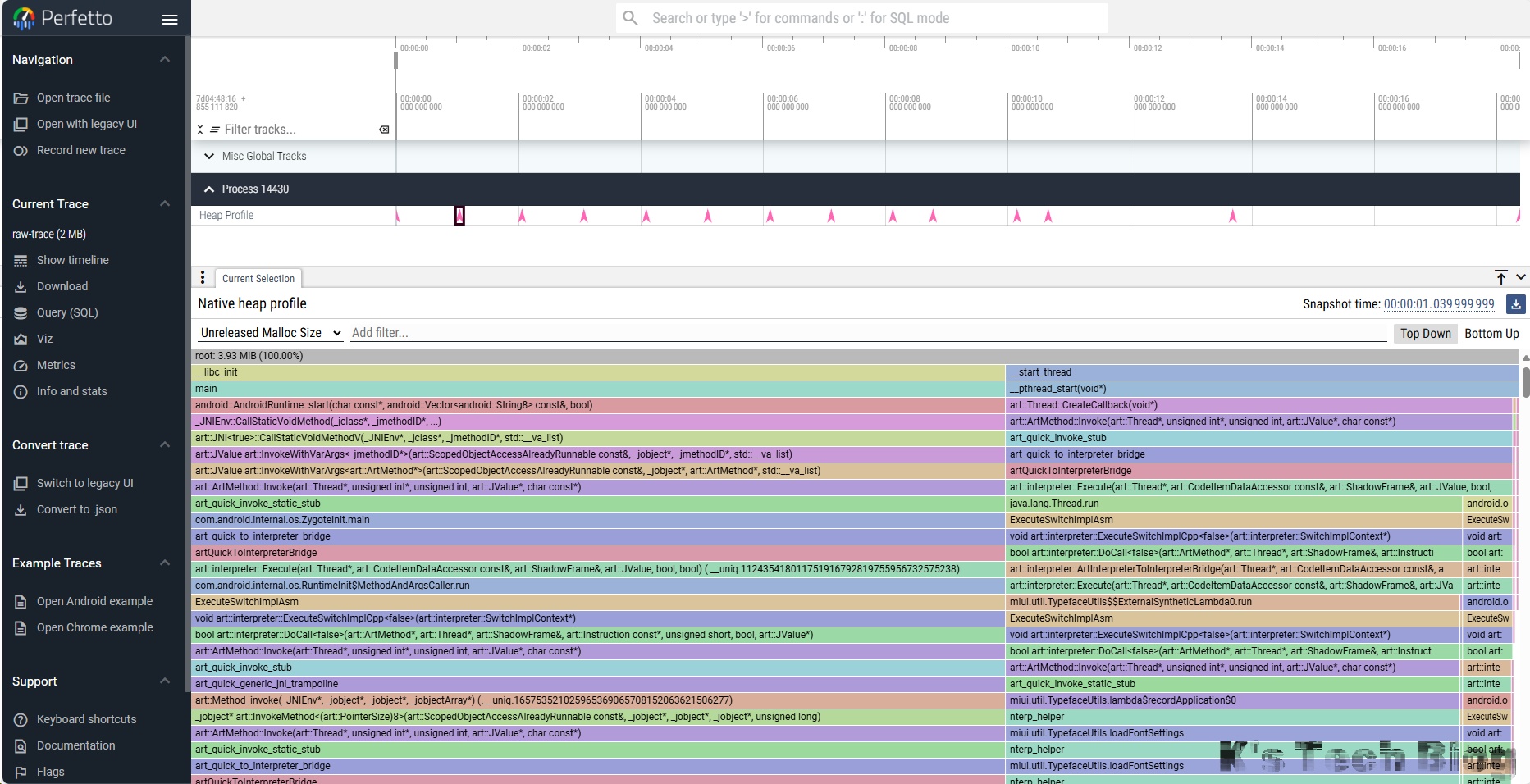
- filer的使用常用的是
SS: ^run_sdk$只显示run_sdk的stack,还有HS: name表示隐藏某些 - 进行分析的话,就是看释放前的抓取点、运行时的抓取点、运行结束后的抓取点,主要看运行后的抓取,分析未释放的堆栈,定位未释放内存的代码位置从而发现内存泄漏问题。
小米CameraBeauty项目分析
Example version: 5d5a16bf00db9788d85231e44dfbde2650164d2c fuai commit id: 287037a2d788551fa018aafb3a4f8e07a18eb297 CNamaSDK commit id: 1a65170344aa5ed075e2c409a56fd4a0b4cb92bd 测试项目: kaihang/AndroidMemoryProfiler ,点击Run SDK运行四次,每个5s抓一次内存信息,分析运行结束之后的内存(释放之后的内存是否有增长)。 抓取的trace信息:symbolized-trace,可以使用 https://ui.perfetto.dev/ 可视化,filter的使用方式参考测试。
分析过程和结果
导入之后,如下图所示,总共有四个运行结束抓取点,只用分析这四个点是否有内存增长即可:
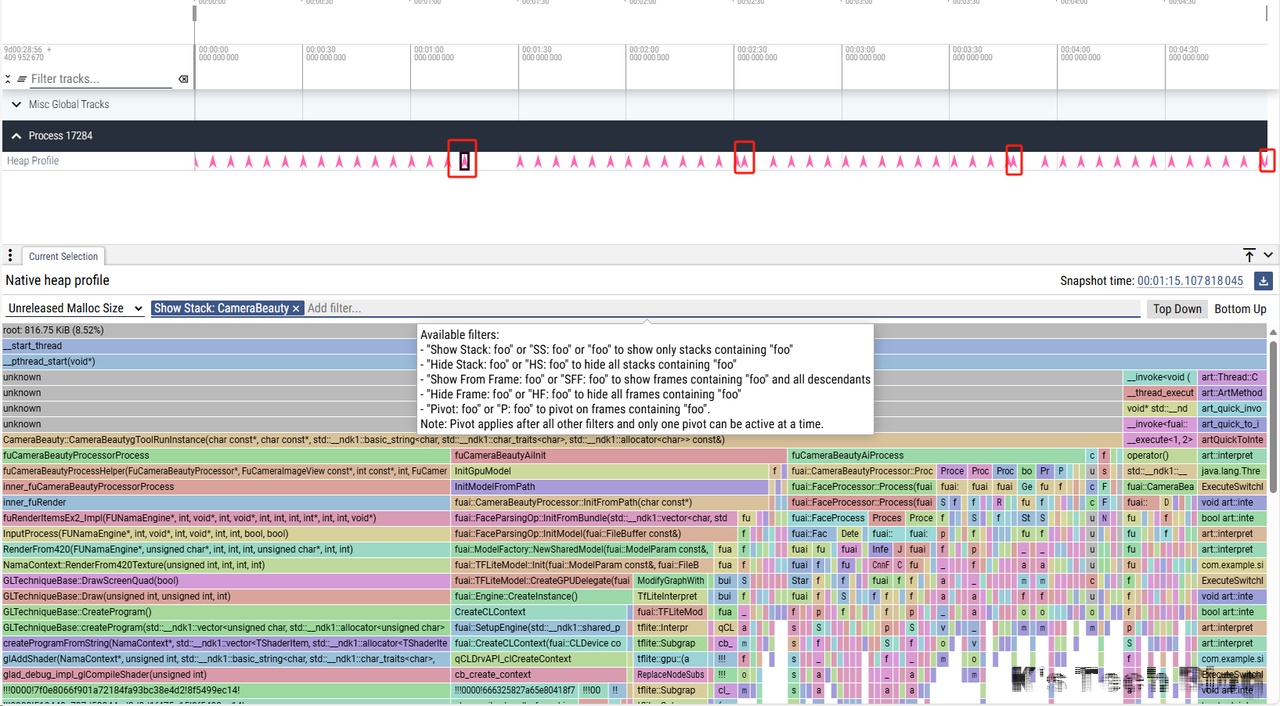
从图中看和SDK相关的Stack只有CameraBeauty,所以只看这个Stack:
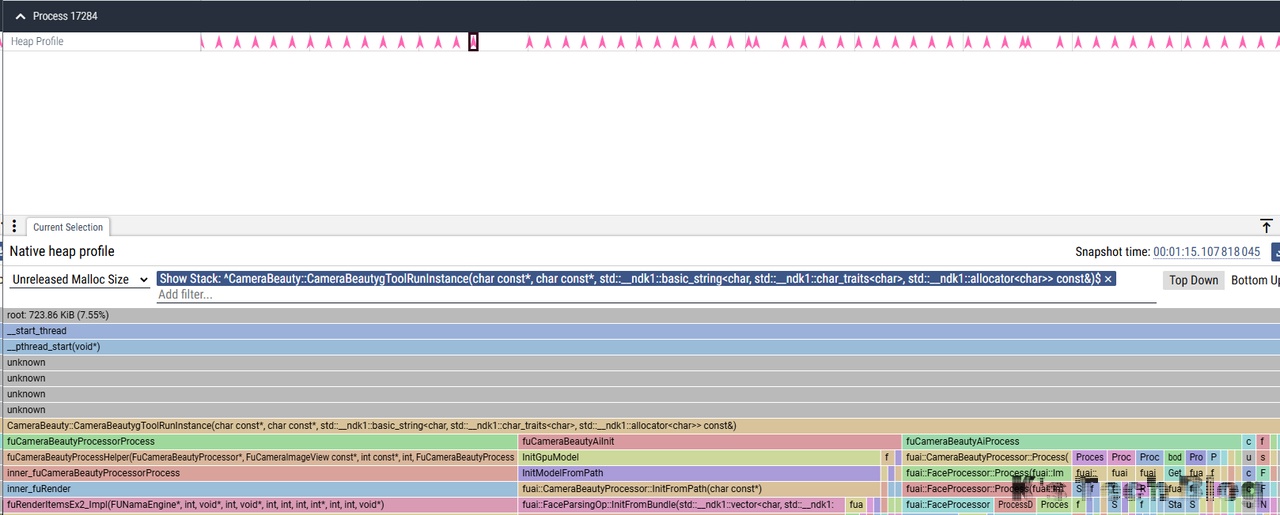
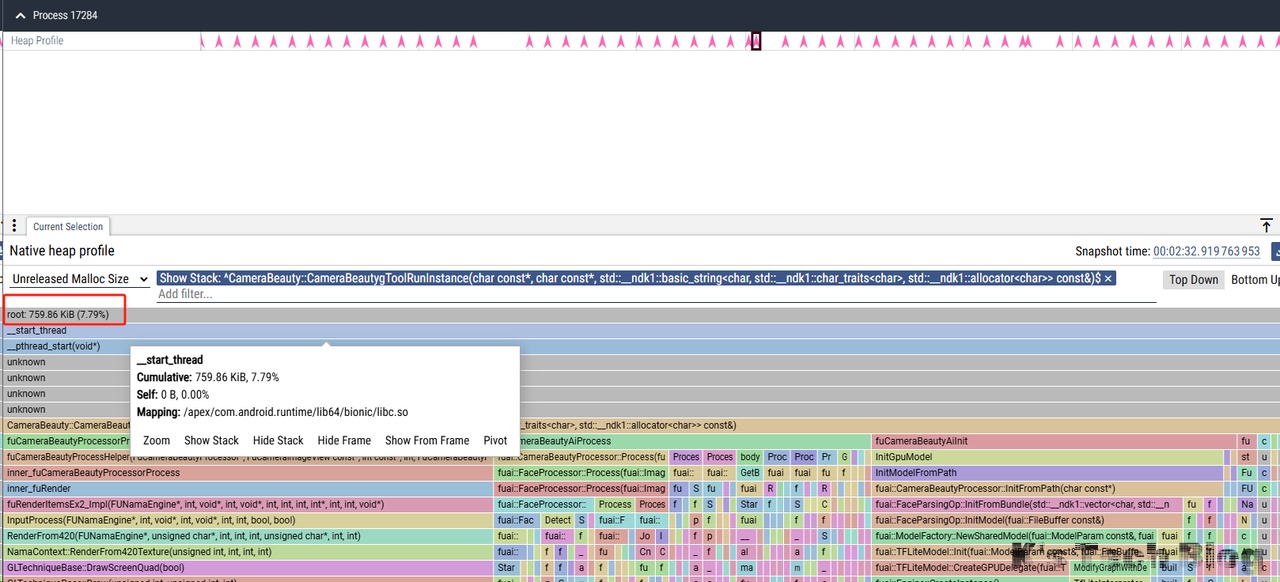
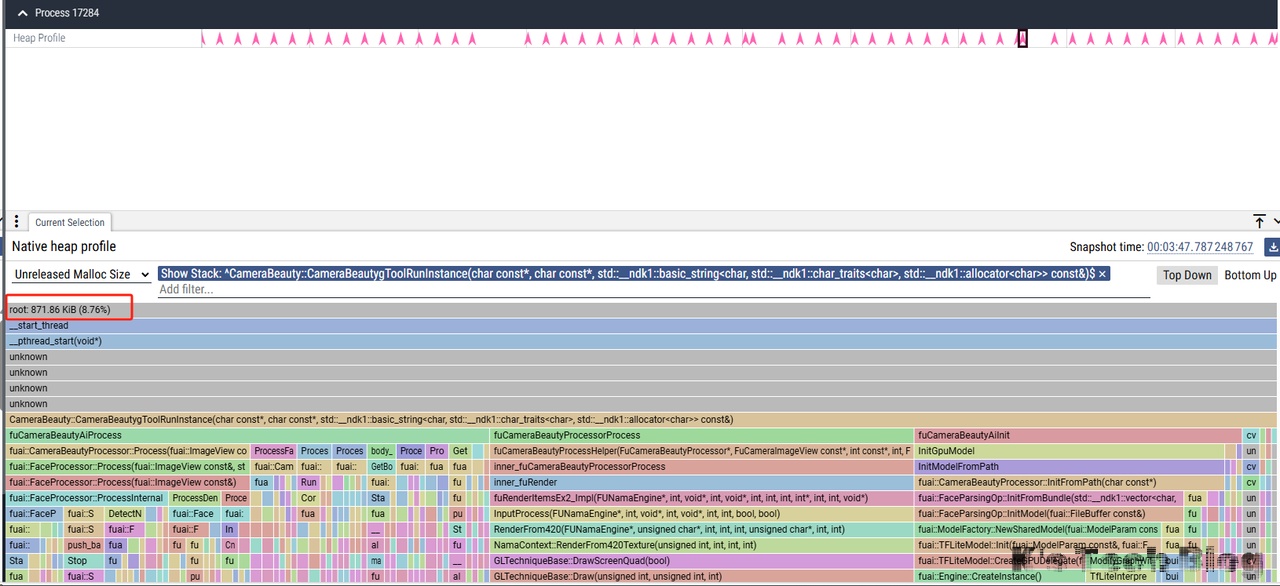
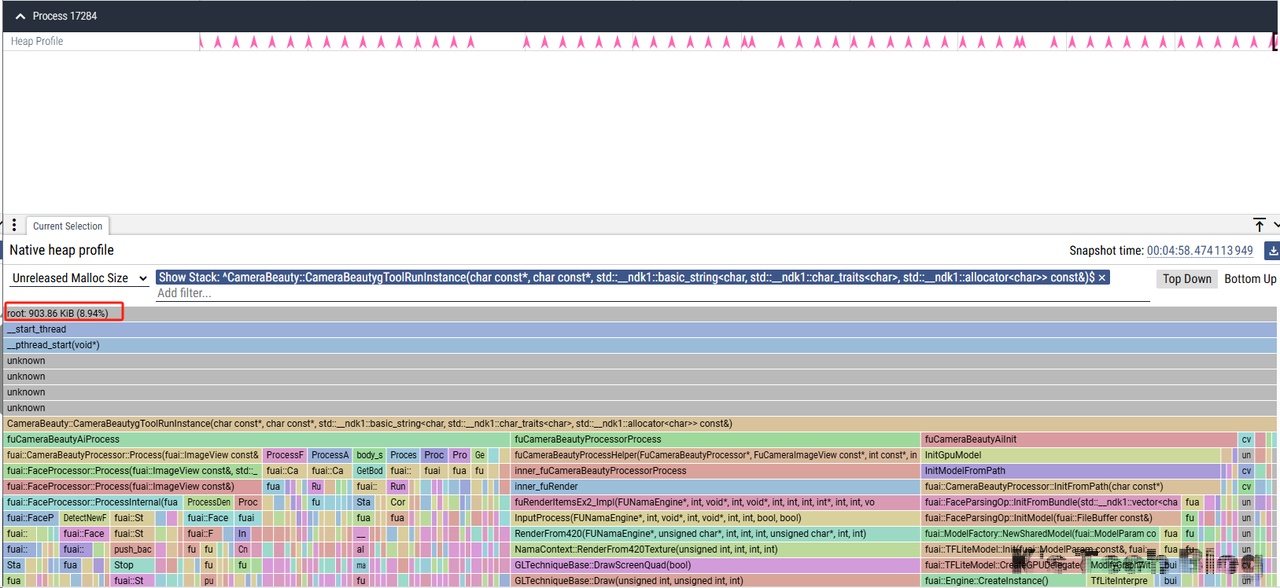 从上面四次释放结果看出,有些微的内存增长,继续向下定位看是否正常。
从上面四次释放结果看出,有些微的内存增长,继续向下定位看是否正常。
| Stack | 第一次结束 | 第二次结束 | 第三次结束 | 第四次结束 |
|---|---|---|---|---|
| CameraBeauty | 723.86KiB | 759.86KiB | 871.86KiB | 903.86KiB |
从子Stack中看出,和SDK相关的只有fuCameraBeautyAiProcess、fuCameraBeautyProcessorProcess、fuCameraBeautyAiInit、fuCameraBeautyCreateProcessorInstance、fuCameraBeautyAiRelease
随后逐个查看:
fuai相关的调用忽略了Profile相关的Stack,Profile一直在push数据,所以一直在增长(filter中加上HS: fuai::StackTime)
| 过程 | 第一次结束 | 第二次结束 | 第三次结束 | 第四次结束 |
|---|---|---|---|---|
| fuCameraBeautyAiProcess | 0KiB | 0KiB | 0KiB | 0KiB |
| fuCameraBeautyAiInit | 180.91 KiB | 180.91 KiB | 180.91 KiB | 180.91 KiB |
| fuCameraBeautyAiRelease | 0KiB | 0KiB | 0KiB | 0KiB |
| fuCameraBeautyProcessorProcess | 290.95 KiB | 290.95 KiB | 290.95 KiB | 290.95 KiB |
| fuCameraBeautyCreateProcessorInstance | 8 KiB | 12 KiB | 4 KiB | 8 KiB |
随后隐藏Profile和cv部分,再次检查,和上述fuCameraBeautyCreateProcessorInstance部分的波动对的上,也即没有内存增长。
| Stack | 第一次结束 | 第二次结束 | 第三次结束 | 第四次结束 |
|---|---|---|---|---|
| CameraBeauty | 479.86 KiB | 483.86 KiB | 475.86 KiB | 479.86 KiB |
结论
无异常内存增长现象,fuai Profile会一直push_back所以在增长,fuai和CNamaSDK均在run结束之后留有部分内存未释放(主要是一些静态变量、OpenGL、OpenCL的资源)
JNI
这里是使用命令行编译JNI的库,不是集成到Android Studio工程中的,Android Studio工程的集成有更方便的方法Android Studio JNI
Example
public class hellojni {
static {
System.loadLibrary("hello"); // loads libhello.so
}
private native void sayHello(String name);
public static void main(String[] args) {
new hellojni().sayHello("Dave");
}
}#ifndef _HELLO_JNI_IMPL_H
#define _HELLO_JNI_IMPL_H
#include <string>
void DoSayHello(const std::string &name);
#endif//_HELLO_JNI_IMPL_H
#include "hellojni_impl.h"
#include <functional>
#include <iostream>
#include <memory>
#include "hellojni.h" // auto-generated by `javah hellojni`
#include <jni.h>
using std::cout;
using std::endl;
using std::function;
using std::shared_ptr;
using std::string;
using std::unique_ptr;
class jstring_deleter {
JNIEnv *m_env;
jstring m_jstr;
public:
jstring_deleter(JNIEnv *env, jstring jstr) : m_env(env), m_jstr(jstr) {}
void operator()(const char *cstr) {
cout << "[DEBUG] Releasing " << cstr << endl;
m_env->ReleaseStringUTFChars(m_jstr, cstr);
}
};
const string ToString(JNIEnv *env, jstring jstr) {
jstring_deleter deleter(env, jstr); // using a function object
unique_ptr<const char, jstring_deleter> pcstr(
env->GetStringUTFChars(jstr, JNI_FALSE), deleter);
return string(pcstr.get());
}
shared_ptr<const char> ToStringPtr(JNIEnv *env, jstring jstr) {
function<void(const char *)> deleter = // using a lambda
[env, jstr](const char *cstr) -> void {
cout << "[DEBUG] Releasing " << cstr << endl;
env->ReleaseStringUTFChars(jstr, cstr);
};
return shared_ptr<const char>(env->GetStringUTFChars(jstr, JNI_FALSE),
deleter);
}
/*
* Class: hellojni
* Method: sayHello
* Signature: (Ljava/lang/String;)V
*/
JNIEXPORT void JNICALL Java_hellojni_sayHello(JNIEnv *env, jobject thisObj,
jstring arg) {
DoSayHello(ToString(env, arg));
// const string name = ToStringPtr(env, arg).get();
// DoSayHello(name);
}
void DoSayHello(const string &name) { cout << "Hello, " << name << endl; }编译方式:
export JDK_INCLUDE_DIR=/home/faceunity/Programs/Android/SDK/jdk1.8.0_202/include
# step 1: compile the .class file with invocation to a native method
javac hellojni.java
# step 2: auto-generate a .h header file from said Java source
javah hellojni
# step 3: make the shared library with the name linked in said Java source, and implementing said native method
g++ -std=c++11 -shared -fPIC -I$JDK_INCLUDE_DIR -I$JDK_INCLUDE_DIR/linux hellojni_impl.cpp -o libhello.so
# step 4: run JVM with java.library.path set to include said shared library
java -Djava.library.path=. hellojni